Guide
Distributed Systems Architecture: Tutorial & Best Practices
Table of Contents
Distributed architecture represents a paradigm shift in the design and deployment of computer systems. It fosters a decentralized approach to computing for enhanced scalability, fault tolerance, and performance. At its core, distributed architecture involves multiple interconnected nodes or computing entities collaborating to achieve a common goal. It distributes computing resources across a network, allowing for more efficient utilization of resources and improved responsiveness.
Distributed systems architecture is particularly crucial in the era of cloud computing and large-scale data processing, where the demand for scalable and resilient systems has become paramount. This article delves into the key principles, benefits, and challenges of distributed architecture, shedding light on its transformative impact on modern computing infrastructures.
Key distributed systems architecture concepts
| Concept | Description |
|---|---|
| Understanding distributed systems | Distributed systems are comprised of multiple independent components (or nodes) that communicate and coordinate with one another to solve a problem or provide a service. |
| Design principles of distributed systems | Decentralization, fault-tolerance, and scalability |
| Components of distributed systems | Real-world distributed systems contain various components, such as a frontend layer, distributed database, and load balancers. |
| Anti-patterns and common traps | Inadequate monitoring, improper sharding techniques, and ineffective data management. |
| Keys to success | Automation, effective implementation of various technologies, and communication between nodes. |
| Future trends | Emerging technologies, methods, and tools, including container orchestration, serverless computing, and consensus algorithms. |
Understanding distributed systems
Distributed systems are a computer science and information technology paradigm where computing resources, data, and processes are spread across multiple interconnected locations. In traditional centralized systems, a single server or processing unit handles all tasks and operations. In contrast, distributed systems distribute the workload across interconnected devices.
In a distributed system, each node (individual device or server) operates independently but collaborates with others to achieve common goals. Communication and coordination between these nodes are crucial for the system to function seamlessly. The decentralization enhances scalability, fault tolerance, and overall system efficiency.


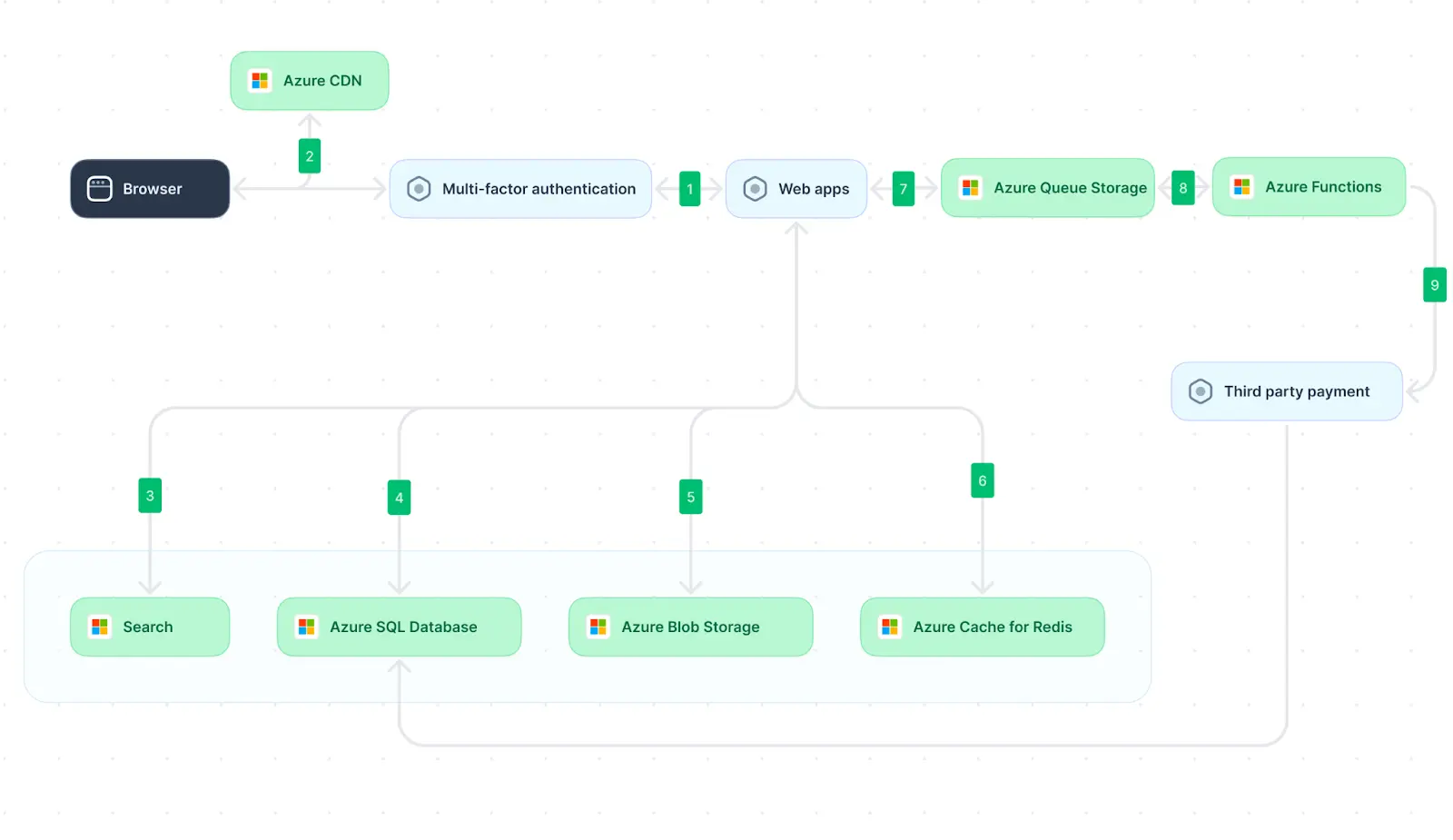
A scalable distributed architecture (adapted from Source)
Organizational needs dictate the type of distributed system architecture implementation necessary for a given requirement. Four common types of distributed system architecture are client-server, peer-to-peer, 3-tier, and N-tier.
Design principles of distributed systems architecture
Designing effective distributed systems requires careful consideration of various features and design elements to ensure seamless operation, scalability, and fault tolerance. Here are key features and design elements crucial for distributed systems:
Scalability
Scalability in distributed systems refers to the system's ability to handle an increasing amount of workload or growth in users and data without sacrificing performance. Achieving scalability is crucial for applications and services to meet the demands of a growing user base and handle varying workloads efficiently. There are two common approaches to scalability.
Horizontal scalability
Horizontal scalability–or "scaling out"–involves adding more nodes or servers to a distributed system. This approach is most common in cloud environments, where new instances can be added to a cluster automatically to handle increased demand.
Vertical scalability
Vertical scalability–or "scaling up"–involves increasing the resources (CPU, RAM, etc.) of existing nodes in the system. This is typically achieved either by adding to the CPU or memory capacity of an existing VM or by purchasing a machine with greater computing resources. Vertical scaling generally requires a much lower initial investment of time and financial resources. However, the primary drawback is that application performance becomes dependent on the resource capacity of a single machine. It introduces a single point of failure, places a hard limit on scalability, and can lead to performance bottlenecks if user traffic exceeds the capabilities of the existing node.
Fault tolerance
Fault tolerance in distributed systems ensures the system's continued operation despite hardware failures, software errors, or network issues. It removes all single points of failure so the system operates normally even when any individual component malfunctions or becomes unavailable. Implementing fault tolerance requires meticulous architecture design and comprehensive planning for worst-case scenarios.
While the intricacies of such a system vary greatly depending on the nature of the application and its underlying infrastructure, there are several common elements.
Replication
Duplicating aspects of a system, such as hardware and software components, network paths, data stores, and power sources, is essential for redundancy. It can also involve replicating entire systems or subsystems to ensure high availability.
Checkpoints
Checkpointing refers to periodically saving the state of a distributed system or application for recovery in case of a failure. You can use checkpoints to roll back to a consistent state after a failure occurs.
Failover
Failover provides a secondary component or service that automatically assumes the functions of the primary system in the event of a primary system failure. This typically involves utilizing a “heartbeat” system between at least two servers. While the “pulse” from the primary server continues, backup servers remain on standby, ready to come online in the event of a disruption in the service.
While fault tolerance is an important design consideration–particularly for critical applications in the realm of finance, emergency response, or healthcare–implementing a system with 100% fault tolerance is costly and unrealistic for many organizations. In these cases, the degree of fault tolerance within the system involves weighing trade-offs between the desired level of system availability and the resources invested in achieving that availability.
Full-stack session recording
Learn more





Consistency
Consistency in distributed systems refers to the uniformity of data across multiple system nodes at any given time. Achieving consistency is challenging due to the inherent nature of distributed environments, where multiple nodes operate concurrently and independently. Because of this, different consistency models have emerged:
- Strong consistency: All nodes in the system see the same data simultaneously. This model ensures that any read operation reflects the most recent write. However, this comes at the cost of higher system complexity that can also impact performance.
- Causal consistency: Preserves the causal relationship between operations. If operation A causally precedes operation B, all nodes will see B after A. This can be considered a compromise between strong and eventual consistency in terms of performance and complexity.
Linearizability
A stronger form of consistency that combines the principles of atomicity and real-time ordering. It ensures that operations appear to be executed instantaneously at some point between their invocation and response.
Consistency protocols
To ensure a consistent view of data in distributed systems, various algorithms and mechanisms can be used:
- Two-phase commit (2PC): A protocol that ensures atomicity and consistency in distributed transactions by having a coordinator coordinate the commit or rollback of all participants.
- Paxos and Raft: Distributed consensus algorithms designed to ensure that a group of nodes can agree on a single value or sequence of values, even in the presence of failures.
- Quorum-based systems: Utilize a voting mechanism where a certain number of nodes must agree on an operation to be considered valid. Quorum systems help balance consistency and availability.
Conflict resolution
In scenarios where concurrent updates lead to conflicts, distributed systems need mechanisms for conflict resolution. Techniques include last-write-wins, vector clocks, and application-level conflict resolution strategies.
Partitioning/Sharding
Partitioning (or sharding) is a fundamental technique in distributed systems that divides and distributes a large dataset across multiple nodes. Each node is responsible for a subset of the data, allowing the system to handle a larger dataset and more concurrent requests.
Partitioning allows a distributed system to scale horizontally. Operations that involve only a subset of the dataset are performed more efficiently. Queries or transactions run in parallel across multiple partitions, improving overall system performance.
Partitioning also enhances fault tolerance by limiting the impact of failures to specific partitions. If a node or partition fails, other partitions can continue to operate independently.
Data partitioning strategies
- Range-based partitioning divides data based on a specific range of values (e.g., ranges of keys or timestamps) but may lead to hotspots if the data distribution is uneven.
- Hash-based partitioning assigns data to partitions based on the hash value of a key but can lead to challenges when range queries are common.
- Directory-based partitioning maintains a separate directory or lookup service that maps keys to partitions, allowing flexibility in changing partitioning strategies without affecting the application layer.
Partitioning in databases
In distributed databases, partitioning is often used to distribute tables across nodes. Database systems like MySQL, PostgreSQL, and Cassandra support different partitioning strategies, such as range, hash, or list partitioning. Some databases provide automatic or manual control over partitioning data, allowing developers to choose the best strategy based on their use case.
Data movement and rebalancing
As the system evolves or the dataset changes, it may be necessary to redistribute data among partitions. Efficient data movement and rebalancing mechanisms are crucial to maintaining performance during such transitions. Automatic rebalancing mechanisms can be implemented to redistribute data when nodes are added or removed from the system.
Cross-partition transactions
In distributed systems with multiple partitions, transactions that span multiple partitions must be carefully managed. Ensuring the consistency of such transactions involves coordination mechanisms, distributed locking, or two-phase commit protocols.
Distributed system architecture components
The complexities of distributed systems increase based on use case and performance requirements. For example, a distributed system architecture for genome research or AI training would be much more complex than that for a small application with a limited user base. However, we give an example architecture of a global e-commerce store to give an overview of the layers that may be present.
Frontend layer
In an e-commerce application, the front end utilizes a globally distributed content delivery network (CDN) to serve static assets such as images, stylesheets, and JavaScript files. This strategy actively reduces latency and accelerates the loading of web pages for users worldwide.
Additionally, the frontend layer incorporates multiple strategically placed load balancers in different regions, efficiently distributing incoming user requests. The global load balancing mechanism routes user requests to the nearest data center or server based on proximity and server load. It guarantees users low-latency access and optimal performance, irrespective of geographical location. Content is cached at edge locations to reduce response times further.
Application layer
The application layer consists of microservices that handle various functionalities such as product catalog management, user authentication, and order processing. These microservices are deployed across multiple regions to minimize response times and improve fault tolerance. Each microservice communicates with others through well-defined APIs, ensuring modularity and ease of maintenance.
For example, an order fulfillment functionality manages the processing of orders and inventory across various fulfillment centers. The service actively employs distributed queues and messaging services to coordinate order processing, ensuring efficient communication of inventory updates and confirmations.
Distributed database
A distributed database system stores the product catalog, user profiles, and transactional data. This architecture involves utilizing a combination of relational databases (e.g., MySQL or PostgreSQL) for structured data and NoSQL databases (e.g., MongoDB or Cassandra) for unstructured or semi-structured data. The distributed database spans multiple data centers globally, ensuring data availability and redundancy.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Security and monitoring
Implementing a distributed security layer protects against common threats such as DDoS attacks and unauthorized access. Security layers commonly include global firewalls, intrusion detection systems (IDS), and distributed denial-of-service (DDoS) mitigation services. Distributed monitoring and analytics tools are employed to gain insights into user behavior, system performance, and potential issues. This involves implementing distributed logging systems, real-time monitoring dashboards, and analytics services to actively track key performance indicators (KPIs) and user engagement.


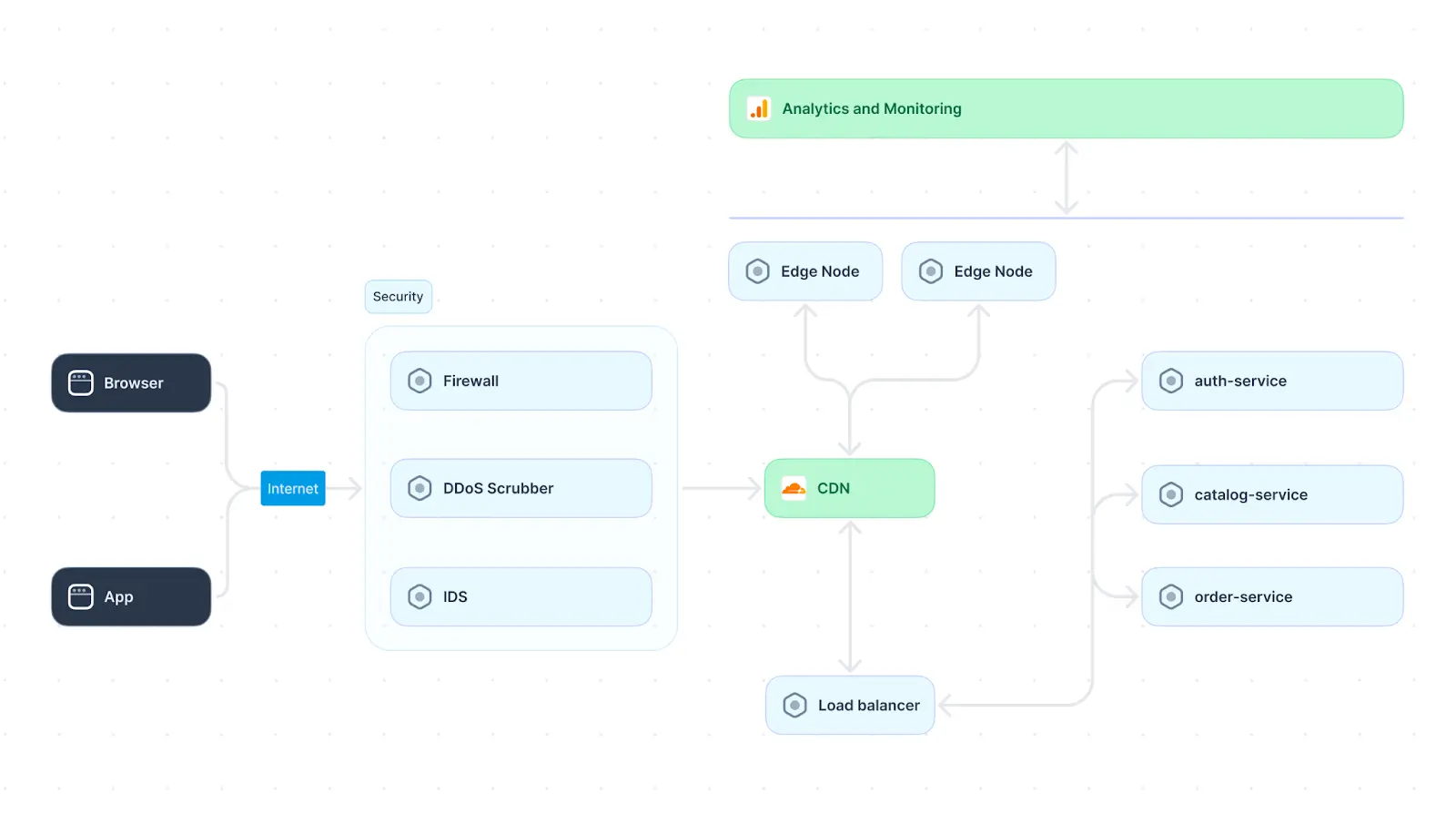
E-commerce architecture solution
Anti-patterns and common traps
Anti-patterns, within software design and development, are recurring practices that initially appear to be solutions but lead to counterproductive outcomes. Recognizing and understanding the anti-patterns in distributed systems architecture is crucial for developers, as it promotes the adoption of more effective solutions in the pursuit of well-designed software systems.
Single point of failure
Single points of failure (SPOF) in distributed systems are elements that, if they fail, can cause the entire system to fail or suffer a significant degradation in performance. For example
- A single central database server failure could lead to data unavailability or loss.
- Centralized authentication systems can prevent users from accessing the entire system.
- If a single network link connects critical components, a failure in that link can isolate parts of the system.
- Centralized network infrastructure can be a single point of failure.
- Failure of critical hardware components (e.g., storage devices, CPUs) in a central location can lead to system failure.
If a system relies on a single load balancer to distribute incoming requests, a failure in the load balancer can disrupt the traffic distribution and overload specific components. A power failure can affect the entire system if a distributed system is hosted in a single data center. Identifying and mitigating such single points of failure is a crucial consideration for ensuring the reliability and resilience of distributed systems.
Inadequate monitoring and logging
Without comprehensive monitoring, it becomes challenging to identify issues or anomalies in the distributed system. Slow performance, errors, or other problems may go unnoticed until they escalate. When issues arise, the lack of detailed logs and monitoring data makes troubleshooting more difficult. Teams may struggle to pinpoint the root cause of problems, leading to increased downtime.
Proactive monitoring helps identify trends, anomalies, or performance degradation early on. You can identify performance bottlenecks or areas for optimization, understand resource usage patterns, and plan for future scaling requirements. It is also crucial for monitoring and responding to security incidents.
Overlooking data partitioning
When data partitioning is not properly considered, several issues may arise. As the dataset grows, nodes may become overloaded, limiting the system's ability to handle increased load by adding more nodes. For instance:
- Certain partitions may become significantly larger than others, resulting in imbalanced workloads, uneven resource utilization across nodes, and performance bottlenecks.
- Queries that require joining data from multiple partitions can be challenging and resource-intensive.
- Some nodes may be underutilized without proper data partitioning, while others are overloaded.
Without effective data partitioning, query planning and optimization become more complex. To address these issues, it's important to carefully design and implement a data partitioning strategy that considers the data's characteristics, query patterns, and system requirements. Properly partitioning data ensures a more even distribution of workloads, facilitates scalability, and contributes to improved performance and reliability in distributed systems.
Ignoring CAP theorem
The CAP theorem, proposed by computer scientist Eric Brewer, states that it is impossible for a distributed system to simultaneously provide all three of the following guarantees:
- Consistency (C): All nodes in the system see the same data simultaneously.
- Availability (A): Every request made to the system receives a response without guaranteeing that it contains the most recent version of the data.
- Partition Tolerance (P): The system continues to operate despite network partitions, which may cause messages between nodes to be delayed or lost.
It's crucial to recognize that optimizing for one aspect may come at the expense of others. Otherwise, it could result in unrealistic expectations about the system's behavior, especially during network partitions or when dealing with issues related to consistency and availability. The operation of the distributed system may become more complex. For example,
- Inconsistent data models may emerge if the system aims to achieve strong consistency in situations where eventual consistency or eventual availability is more appropriate.
- Overemphasis on consistency at the cost of availability could lead to increased downtime or decreased responsiveness during network partitions or failures.
- Neglecting partition tolerance in system design can make systems more vulnerable to network issues.
Failing to consider CAP may lead to suboptimal system design choices, as the design should align with the specific requirements and priorities of the application. In some cases, systems may opt for eventual consistency, prioritizing availability and partition tolerance over strong consistency. In other cases, systems may prioritize strong consistency, accepting potential availability issues during partitions. The key is to make conscious design decisions based on a clear understanding of the CAP theorem and its implications for distributed systems.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEUncontrolled data growth
Failing to effectively manage data growth in distributed systems can lead to a range of issues,
- Performance bottlenecks affecting the speed at which data can be retrieved and processed.
- Resources such as storage, memory, and processing power may be inefficiently utilized.
- Duplicate data and outdated records can compromise data integrity and make maintaining a single, accurate source of truth challenging.
- Difficulty in scaling horizontally or vertically to accommodate growing datasets.
You may also experience unexpected increases in operational costs, such as storage, data transfer, and costs associated with maintaining and upgrading hardware. It's important to implement sound data management practices in distributed systems to address these challenges. This includes implementing data pruning and archiving strategies, optimizing data structures and indexing, and regularly reviewing and refining data retention policies. Additionally, monitoring and forecasting data growth can help anticipate future needs and proactively address potential issues before they impact system performance and reliability.
Keys to success
Successful implementations of distributed systems architecture require careful consideration of several vital factors.
Comprehensive planning
Successful implementation of distributed systems architecture begins with thorough planning. Define clear project goals, identify key stakeholders, and thoroughly analyze system requirements. Establish a roadmap that outlines the deployment strategy, potential challenges, and milestones. A well-thought-out plan provides a solid foundation for the entire project.
Scalable and flexible design
Ensuring a scalable and flexible design is crucial for building systems that can adapt to changing requirements and handle increased workloads. For example, you can adopt a microservices architecture, breaking down the system into small, independent services. Each service can be developed, deployed, and scaled independently. You can also use different types of databases (polyglot persistence) based on the specific requirements of each service or component. This flexibility allows selecting the most suitable data storage technology for each use case.
It is also important to containerize applications using technologies like Docker and orchestrate them with tools like Kubernetes. Containers provide consistency across different environments, and orchestration allows for dynamic scaling and management.
Implement versioning for APIs to ensure backward compatibility when introducing changes. This enables a phased approach to rolling out new features and updates without disrupting existing clients.
Emphasis on security
Security is a non-negotiable aspect of distributed systems architecture, ensuring resilience and trustworthiness. Implement robust authentication mechanisms, encryption protocols, and access controls to safeguard data integrity and protect against unauthorized access. Regularly audit the system for vulnerabilities and adhere to security best practices throughout the development lifecycle. Prioritizing security of the distributed system.
Documentation and knowledge transfer
Document the architecture, design decisions, and best practices. This promotes a shared understanding of the distributed system’s intricacies, helps onboard new team members more quickly, and allows development teams to plan for new features and scalability.
Continuous testing and optimization
Implement continuous testing processes to identify and address potential issues early in the development lifecycle. Continuously optimize the system based on real-world usage and performance metrics.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEMonitoring, analytics, and automation
Implement robust monitoring and analytics tools to gain real-time insights into the performance and health of the distributed system. Proactive monitoring helps identify potential issues before they escalate, enabling timely intervention. Additionally, incorporate automation into deployment, scaling, and recovery processes to streamline operations and reduce the risk of human error. Automation enhances efficiency and ensures a more responsive and adaptive distributed system.
Modern trends
The field of distributed system architecture is dynamic and continually evolving, driven by emerging technologies, innovative methods, and advancements in tooling.
Serverless computing abstracts infrastructure management, allowing developers to focus solely on code. Platforms like AWS Lambda, Azure Functions, and Google Cloud Functions enable the execution of functions in a serverless environment, promoting a more event-driven and cost-effective approach. Innovations are emerging to support stateful applications in serverless architectures. Projects like AWS Step Functions and Azure Durable Functions facilitate the orchestration of stateful workflows in serverless environments, expanding the scope of use cases.
Edge computing involves processing data closer to the source, reducing latency and bandwidth usage. Tools like AWS IoT Greengrass, Azure IoT Edge, and Google Cloud IoT Edge extend cloud capabilities to the edge, enabling distributed processing in IoT and other applications.
Integrating AI and machine learning into distributed systems is gaining traction. Technologies like TensorFlow Serving and MLflow enable deploying and managing machine learning models within distributed architectures, fostering intelligent decision-making.
Leveraging new tools like Multiplayer can bring an increased level of productivity to teams designing and developing distributed systems. Multiplayer captures full-stack session recordings which include frontend screens, backend traces, logs, metrics, and full request/response content and headers, etc. - all correlated in a single session.
Each session replay includes a service map showing the exact path of a request or error across your system. The same technology powers their system dashboard, which automatically detects and visualizes your system’s logical architecture, components, APIs, dependencies, and environments. This allows you to zoom out to see the “big picture” and drill down into finer details.
With this context, developers can quickly understand how distributed services interact in practice, diagnose failures across boundaries, and evolve complex systems with confidence. Multiplayer also supports modern workflows like AI-assisted bug fixing, test failure analysis, and feature development based on real system behavior, reducing the need to manually reconstruct flows from fragmented observability data. This helps teams build more resilient and scalable architectures while keeping system understanding accessible to every developer and QA professional.
Conclusion
Distributed systems architecture finds applications in various sectors, including cloud computing, the Internet of Things (IoT), and large-scale data processing. It continues to evolve with emerging technologies, addressing challenges through innovative methods, tools, and best practices. Understanding the principles of distributed systems architecture is crucial for designing robust, scalable, and resilient systems in our interconnected digital landscape.