Guide
Platform Engineering vs. DevOps: Tutorial & Comparison
Table of Contents
DevOps and platform engineering aim to enhance efficiency, streamline workflows, and accelerate reliable software delivery. However, they approach these goals through distinct principles and practices.
Although platform engineering is sometimes presented as a replacement or alternative to DevOps, the reality is more nuanced: rather than replacing DevOps, platform engineering builds upon it by using its best practices and automating infrastructure provisioning to make the software development process more efficient. In other words, once software delivery and operations meet the end-user expectations, organizations can afford to turn their attention to making software developers more productive.
In this article, we explore the relationship between platform engineering and DevOps. It will help you obtain a comprehensive understanding of the concepts, learn key indicators for when platform engineering becomes beneficial, and gain practical knowledge about how the two practices complement each other in various scenarios.
Summary of key platform engineering vs DevOps concepts
The table below summarizes how we will compare platform engineering and DevOps. In the sections that follow, we explore each concept in greater depth.
| Concept | Description |
|---|---|
| A brief history | DevOps emerged in the late 2000s to increase collaboration between previously siloed development and operations teams. As software systems grew in complexity, platform engineering was introduced to address the limitations of DevOps at scale. |
| Comparison of approaches | Platform engineering and DevOps aim to improve developer productivity, automation, and operational efficiency by streamlining software delivery and infrastructure management but have differences in key areas, including their end users and team structures. |
| When should organizations introduce platform engineering? | Platform engineering empowers organizations to respond more quickly to developer needs. It often becomes necessary when existing DevOps practices hinder developer productivity and increase operational overhead. |
| Examples of introducing platform engineering into an organization | Spotify, Google, and many other organizations have effectively adopted platform engineering to manage and deploy microservices at scale. |
| How to introduce platform engineering | While platform engineering can improve DevOps scalability and developer experience, poor implementation leads to siloed environments, bureaucracy, and reduced agility. Organizations should focus on collaboration, transparency, and developer enablement to ensure a smooth transition. |
A brief history
To understand the relationship between DevOps and platform engineering, it is helpful to examine the history of both approaches and what problems each intends to solve.
The introduction of DevOps
DevOps emerged to solve workflow problems between siloed development and operations teams. Before the DevOps movement, the development team was exclusively responsible for writing business logic and building the core application, while operations managed the underlying runtime and infrastructure, an approach that led to development delays. The development team was forced to pause work while waiting for operations to make infrastructure adjustments, and operations had to wait on development for any application code changes that influenced deployment.
The concept of DevOps was introduced to address these challenges. In this approach, rather than having separate development and operations teams, one DevOps team owns the application, runtime, and underlying infrastructure to optimize development speed and flexibility.
The problem with DevOps
As applications continued to scale and grow in complexity, so did their infrastructures and the time needed to set up and maintain them. Today, setting up a modern application stack is a weighty task that often involves steps like:
- Setting up CI/CD
- Writing and maintaining Infrastructure-as-Code (IaC) scripts
- Configuring logging and monitoring
- Adding security scans
- Spinning up Kubernetes clusters, maintaining Helm charts, managing Docker repositories, etc.
In a pure DevOps model, each project would require the DevOps team to perform each step above. This demands broad expertise within every team and introduces significant cognitive load. As a result, teams often would develop their own ad hoc approaches to infrastructure, leading to inconsistencies and a lack of standardization—an issue that becomes especially problematic at scale.
The rise of platform engineering
Platform engineering addresses these challenges by standardizing tools and processes for deploying and operating applications across teams. Its core goal is to reduce complexity and enable self-service through internal developer platforms (IDPs). These platforms provide functionality for infrastructure and environment management, allowing developers to focus on writing code while maintaining security, consistency, and scalability.
Rather than replacing DevOps, platform engineering enhances it by aligning DevOps practices across the organization and enabling them to scale more effectively.


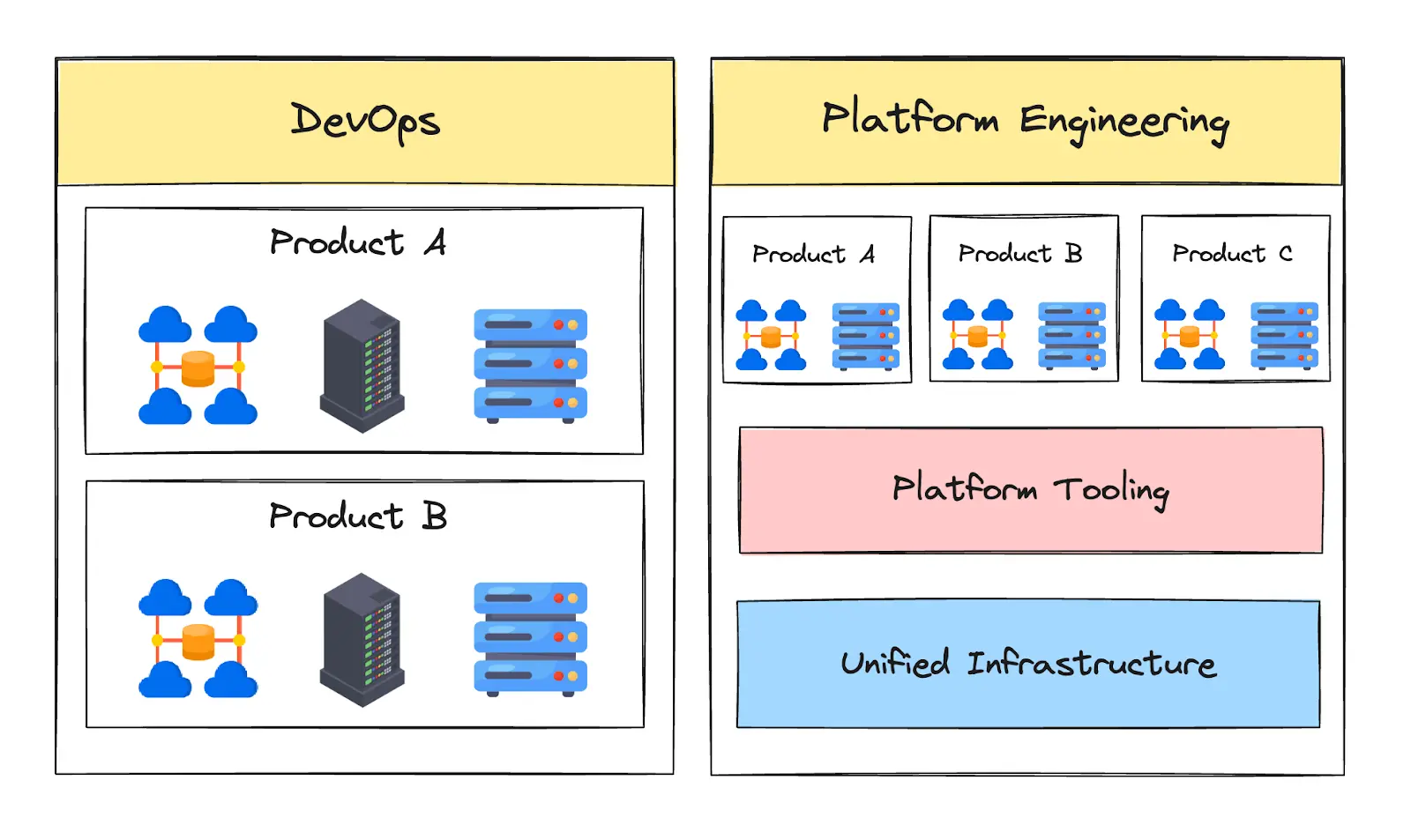
Platform engineering standardizes tooling and infrastructure management
Comparison of approaches
Now that we have examined the motivations behind both platform engineering and DevOps, let’s take a look at each practice through the following points of comparison, summarized in the table below.
| Point of comparison | DevOps | Platform Engineering |
|---|---|---|
| Primary goal | Culture and process optimization | Streamlined developer workflows through platforms |
| End users | Developers, operations teams, QA engineers, security engineers, and even business stakeholders | Developers and engineering teams |
| Team structure | Cross-functional teams working together | Dedicated platform teams supporting developers |
Primary goal
DevOps is a broad cultural and operational philosophy focused on improving collaboration between development and operations teams. Its core goals include enabling continuous integration, delivery, and deployment (CI/CD) while fostering shared responsibility for quality, security, and performance.
Platform engineering, by contrast, is about building standardized, scalable internal platforms that treat infrastructure as a product. Its main objective is to reduce the complexity of provisioning, deploying, and operating applications by providing developers with self-service tools that abstract away infrastructure concerns.
End users
DevOps supports a wide range of stakeholders, including developers, operations, QA, and security teams. Its goal is to ensure speed, reliability, and compliance across the delivery lifecycle by:
- Streamlining software delivery through CI/CD pipelines
- Promoting communication across all teams (development, operations, QA, etc.) to foster a shared responsibility for software quality
- Implementing effective tools and practices for consistent monitoring, observability, infrastructure management, and security within a single project
Platform engineering builds on these principles but primarily serves developers. It empowers developers to adopt DevOps practices more consistently and effectively by providing self-service internal developer platforms (IDPs) that support them throughout the software delivery cycle. This includes:
- Abstracting and automating infrastructure tasks, such as provisioning cloud resources, managing environments, and controlling access
- Providing interfaces that allow developers to deploy code consistently and repeatably without needing intervention from operations
- Standardizing and automating practices for CI/CD, monitoring, observability, and security across teams
Platform engineering can be conceptualized as mature DevOps at scale. It extends and formalizes DevOps across different projects and development teams that share needs for infrastructure, tools, and workflows.
Team structure
Platform engineering and DevOps teams have different structures based on their responsibilities. Platform engineering teams are dedicated groups that build and maintain IDPs, treating developers as customers and focusing on scalable, self-service infrastructure. They typically include platform engineers, site reliability engineers (SREs), and infrastructure specialists who automate and standardize organizational environments.
Adopting DevOps practices does not necessarily require a dedicated DevOps team. DevOps is a cultural shift toward creating an environment of shared responsibility for the entire application lifecycle, from development through deployment and monitoring. This means that DevOps practices can be adopted gradually by encouraging communication, automation, and a culture of collaboration between development and operations teams without altering existing team structures.
When should organizations introduce platform engineering?
An organization should consider introducing platform engineering when an application reaches a level of complexity and scale that requires a more structured approach to developer enablement and infrastructure management than DevOps can provide. As discussed previously, the core goal of platform engineering is to standardize practices across teams to reduce the development burden, required expertise, and cognitive load on each individual team. Let’s explore key areas where platform engineering can have a significant impact.
Infrastructure and operations
Scaling infrastructure and operations becomes increasingly complex as organizations grow. Without a consistent, centralized approach, teams may encounter performance bottlenecks, operational inefficiencies, and escalating infrastructure costs.
Consider a rapidly expanding ecommerce company with dozens of development teams managing thousands of microservices across multiple cloud providers. Without standardization, teams inevitably take different approaches when scaling their infrastructures and configuring monitoring and alerting tools. Inconsistent practices across teams mean that developers must understand completely different tools, configurations, and processes when attempting to understand execution across services, which makes troubleshooting incidents across services time-consuming and error-prone. In addition, teams may make inconsistent or even suboptimal decisions regarding provisioning, which can lead to resource sprawl and cost inefficiencies.
Full-stack session recording
Learn more





When platform engineering teams provide IDPs with unified and automated policies for infrastructure, scaling, monitoring, alerting, and environment management, these challenges are mitigated. For example, the Terraform module below provisions a compute instance, automatically installs a Prometheus Node Exporter, and registers the service in a centralized monitoring system.
# modules/standardized_compute_instance/main.tf
resource "aws_instance" "app" {
ami = var.ami_id
instance_type = var.instance_type
tags = merge(var.tags, {
"Monitoring" = "enabled"
"Environment" = var.environment
})
user_data = <<-EOF
#!/bin/bash
yum install -y prometheus-node-exporter
systemctl enable node_exporter
systemctl start node_exporter
EOF
}
resource "aws_security_group" "monitoring" {
name = "${var.name}-monitoring-sg"
description = "Allow Prometheus scraping"
ingress {
from_port = 9100
to_port = 9100
protocol = "tcp"
cidr_blocks = [var.prometheus_cidr]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
variable "ami_id" {}
variable "instance_type" {}
variable "tags" {
type = map(string)
default = {}
}
variable "environment" {}
variable "name" {}
variable "prometheus_cidr" {}A module like this allows teams to develop different services modularly across different environments while providing standardization in the areas of monitoring setup (using Prometheus Node Exporter), automated security configuration (port 9100 access), and standardized tagging and environment awareness.
Multi-cloud deployments
Platform engineering can also provide cloud-agnostic tooling to deploy workloads to different cloud providers. The code block below shows how platform engineers can create abstracted modules that use different cloud providers conditionally.
# modules/compute_instance/variables.tf
variable "cloud" {
type = string
default = "aws"
}
# modules/compute_instance/main.tf
module "aws_instance" {
source = "./aws"
count = var.cloud == "aws" ? 1 : 0
# pass shared variables
}
module "gcp_instance" {
source = "./gcp"
count = var.cloud == "gcp" ? 1 : 0
# pass shared variables
}
module "azure_instance" {
source = "./azure"
count = var.cloud == "azure" ? 1 : 0
# pass shared variables
}Using the code above, developers can specify the cloud provider they are targeting:
module "order_service_instance" {
source = "git::https://example.com/modules/compute_instance.git"
cloud = "gcp"
# common config
}This approach has the benefit of abstracting away which cloud provider is being used. Although this is a relatively simple example, such modules can be extended to centralize provisioning, scaling, cost tracking, observability, and policy enforcement practices. This allows developers to use the same interface and follow the same practices regardless of whether the workload runs on AWS, GCP, or Azure.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Security and compliance
Teams that prioritize security often implement the DevSecOps approach, which aims to shift security left, automate security testing, and integrate security practices across the entire development lifecycle. Like DevOps, these practices are often effective within a single project, but as organizations scale and the number of teams and services grows, the lack of standardized DevSecOps practices between projects (e.g., inconsistent tooling or fragmented processes) can lead to duplicated effort, security vulnerabilities, and development bottlenecks.
For example, consider a company with multiple development teams working on different microservices:
- Team A uses Snyk for dependency scanning and Trivy for container image scanning.
- Team B uses OWASP Dependency-Check and Aqua Security.
- Team C runs manual security reviews with no automated scanning.
In addition, each team runs pipelines in different CI/CD tools (GitHub Actions, GitLab CI, Jenkins) with varied levels of security testing coverage.
A platform team can address these issues through a shared IDP that provides pre-approved CI/CD pipeline templates with built-in features:
- Static code analysis (e.g., SonarQube, Semgrep)
- Dependency scanning (e.g., Snyk)
- Container image scanning (e.g., Trivy)
Such a platform could also handle secrets management and policy enforcement (e.g., with HashiCorp Vault and OPA) and consolidate observability and compliance tooling to automatically collect and visualize logs, metrics, and audit trails.
Service discovery
A frequent use case for IDPs is within distributed environments with dozens, hundreds, or even thousands of services. When service discovery and documentation are fragmented in such environments, developers struggle to find, understand, and safely integrate with existing services. The lack of complete knowledge of what is already in place creates issues when they attempt to add new services or debug existing integrations.
An IDP can alleviate these pain points by centralizing service metadata, ownership, API documentation, and dependency mapping. However, doing so effectively comes with significant overhead. Initially, the platform team must collect and standardize metadata across services, connect source systems (Git, CI/CD, Kubernetes, etc.) to feed into the platform, tag and classify services appropriately, create documentation, and build an interface to present this information in a digestible manner. As the platform and application services evolve, platform engineers must maintain documentation and ensure that the IDP stays in sync with the real-world system.
For teams hoping to simplify service discovery without this overhead, tools like Multiplayer’s system dashboard can help. The system dashboard utilizes data collected via OpenTelemetry to automatically discover, track, and document your system's architecture. This provides many benefits:
- You can reverse-engineer your entire system by automatically detecting all components, APIs, dependencies, platforms, and environments.
- It’s possible to maintain real-time, up-to-date visualizations of your system architecture without the overhead of manual updates.
- You’ll be able to identify and address architectural drift by comparing the real-world system with your documented architecture.


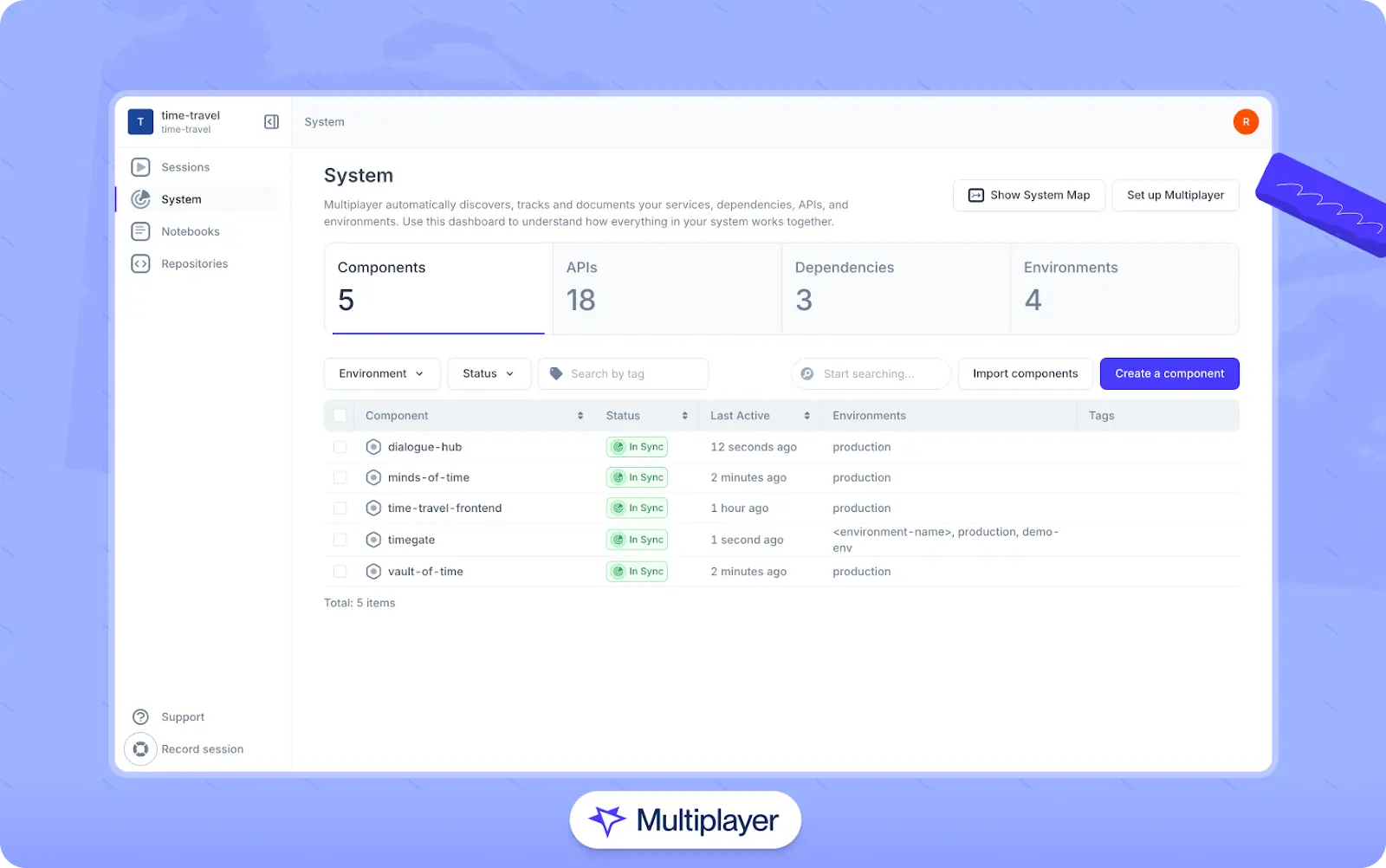
Multiplayer’s system dashboard
Examples of introducing platform engineering into an organization
Many organizations have transitioned from a traditional DevOps model to platform engineering to address scalability, standardization, and challenges related to developer experience. Here are some real-world examples to illustrate this shift.
Spotify: Backstage as an internal developer platform (IDP)
As Spotify scaled, managing thousands of services and coordinating across hundreds of distributed engineering teams became increasingly complex. Developers faced challenges with service discovery, documentation, and infrastructure setup, while DevOps teams struggled to handle support requests related to infrastructure provisioning, CI/CD setup, and troubleshooting.
To address these challenges, Spotify created Backstage, an IDP that centralizes service management, documentation, and monitoring. Backstage was initially developed in-house and later open-sourced. Its core features include:
- A centralized service catalog, which simplifies service discovery and understanding service dependencies
- Standardized integration of tools like CI/CD pipelines and Kubernetes for consistent deployments, management, and monitoring
- Customizable plugins for integrating cloud provisioning, deployment, and monitoring tools
- Prebuilt templates (for IaC, CI/CD configs, monitoring hooks, etc.) that allow developers to spin up new microservices and components easily
- Integration with popular tools like Jenkins, GitHub Actions, and Docker to reduce system complexity
For Spotify, the primary benefits of adopting Backstage were increased developer efficiency and collaboration, faster onboarding, consistency in service management, increased operational efficiency, and reduced development costs through automation and reduced manual intervention.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREELarge financial institution: Moving to an internal cloud platform
Another real-world example involves a large financial institution. As the institution expanded its digital services, it faced significant challenges in managing complex infrastructure across multiple teams. Its reliance on traditional IT operations resulted in long provisioning times, inconsistent security policies, and operational inefficiencies. As a result, developers struggled with fragmented workflows, compliance issues, and manual processes. The institution needed a scalable, centralized solution to address these challenges and streamline both delivery and infrastructure management.
The organization transitioned to an internal cloud platform with an emphasis on governance and compliance. The platform provided on-demand infrastructure, standardized security controls, and automated workflows through the following features:
- Self-service infrastructure provisioning: Developers could quickly generate compute, storage, and networking resources on demand, reducing reliance on operations and eliminating long provisioning times.
- Standardized security and compliance controls: The platform enforced security policies, access controls, and compliance requirements (e.g., GDPR, PCI-DSS) through automated checks.
- Automated CI/CD pipelines: Integrated pipelines ensured faster, more reliable software releases with built-in security and compliance validation.
- Centralized observability and monitoring: Real-time logging, monitoring, and incident response tools helped teams proactively manage performance and resolve issues.
- Multi-cloud and hybrid cloud support: The platform supported both on-premises data centers and public clouds (AWS, Azure, Google Cloud), offering flexibility and regulatory compliance.
In short, the organization re-envisioned how it designs and manages its infrastructure to accelerate software delivery while prioritizing security, scalability, and developer efficiency. These strategies resulted in improved productivity, faster time to market, better security and compliance, and cost savings.
Google: Borg as an early platform
A final example involves Google. As the organization grew into one of the world’s largest tech companies, it encountered massive challenges in infrastructure management, scalability, and reliability. With thousands of engineers and millions of services deployed across global data centers, manual infrastructure management became unsustainable.
To address these challenges, Google developed Borg, its internal container orchestration system, beginning in 2003. Although Borg was initially a small-scale internal project, it grew with Google’s expanding services and eventually became the foundation for virtually all of Google’s internal systems. It also led to the development of Kubernetes.
While Borg predated the wider engineering community’s movement toward platform engineering, Borg can be considered an early large-scale example of an IDP. Borg provided declarative deployment, resource scheduling, and fault tolerance without requiring engineers to manually provision infrastructure. It also automatically enforced policies around resource limits, scheduling constraints, and priority classes. Each of these practices is consistent with platform engineering’s goal of allowing developers to build features quickly while ensuring compliance, reliability, and cost-efficiency.
How to introduce platform engineering
As we have seen, organizations should consider adopting platform engineering when existing DevOps practices are insufficient. This often manifests as developers spending excessive time handling infrastructure complexities, debugging inconsistent environments, or navigating fragmented tooling instead of writing and shipping code.
However, as with any significant change to internal development processes, it is essential to introduce platform engineering in the right way. Let’s take a look at a few best practices that help avoid common pitfalls.
Build gradually
Platforms that are built and adopted too quickly can become bloated or costly or may face developer resistance if there is a sudden overhaul of tools and workflows. To avoid this, organizations should introduce platform engineering at the right time and in a phased, iterative manner. Resist the temptation to anticipate every possible future need—opt for modular, extendable designs instead.
Start by solving the most painful and high-impact problems—like standardizing CI/CD pipelines or automating secrets management—so teams can benefit immediately without waiting for a complete platform. Roll out the platform gradually to allow developers to adjust to new workflows, and ensure that there are mechanisms in place to collect feedback and continuously improve.
Prioritize developer experience
The primary goal of IDPs is to improve developer experience by treating developers like customers and optimizing their productivity and autonomy. If the platform is cumbersome, unintuitive, or lacks proper documentation, developers may resort to workarounds, defeating its purpose.
A well-designed self-service interface, clear documentation, and intuitive tooling can significantly improve usability. Additionally, embedding DX principles such as reducing cognitive load, simplifying onboarding, and ensuring seamless integrations helps create a platform developers want to use.
Leverage existing solutions
A frequent pitfall in platform engineering is overbuilding: creating complex, custom platforms overloaded with features that developers don’t need. Teams can avoid this by focusing on their most critical pain points and leveraging proven, off-the-shelf tools instead of building every component in-house.
For example, CI/CD can be streamlined with tools like GitHub Actions or Argo CD, while IaC is well-supported by Terraform and Pulumi. For secrets management, consider using HashiCorp Vault or cloud-native options like AWS Secrets Manager, Azure Key Vault, and Google Secret Manager.
For teams hoping to prioritize visibility and debugging, tools like Multiplayer offer advanced capabilities. As we have already seen, Multiplayer’s system dashboard assists with service discovery, automatically creates architecture diagrams, and summarizes information across components, APIs, dependencies, platforms, and environments.
In addition, Multiplayer’s full stack session recordings allow developers and end users to capture frontend user actions correlated with backend backend traces, metrics, logs, and complete request/response data. Sessions can be annotated with sketches, on-screen text, and timestamp notes so that developers can highlight relevant API calls, add notes to UI transitions, flag relevant traces, or clarify expected behavior directly within the replay.

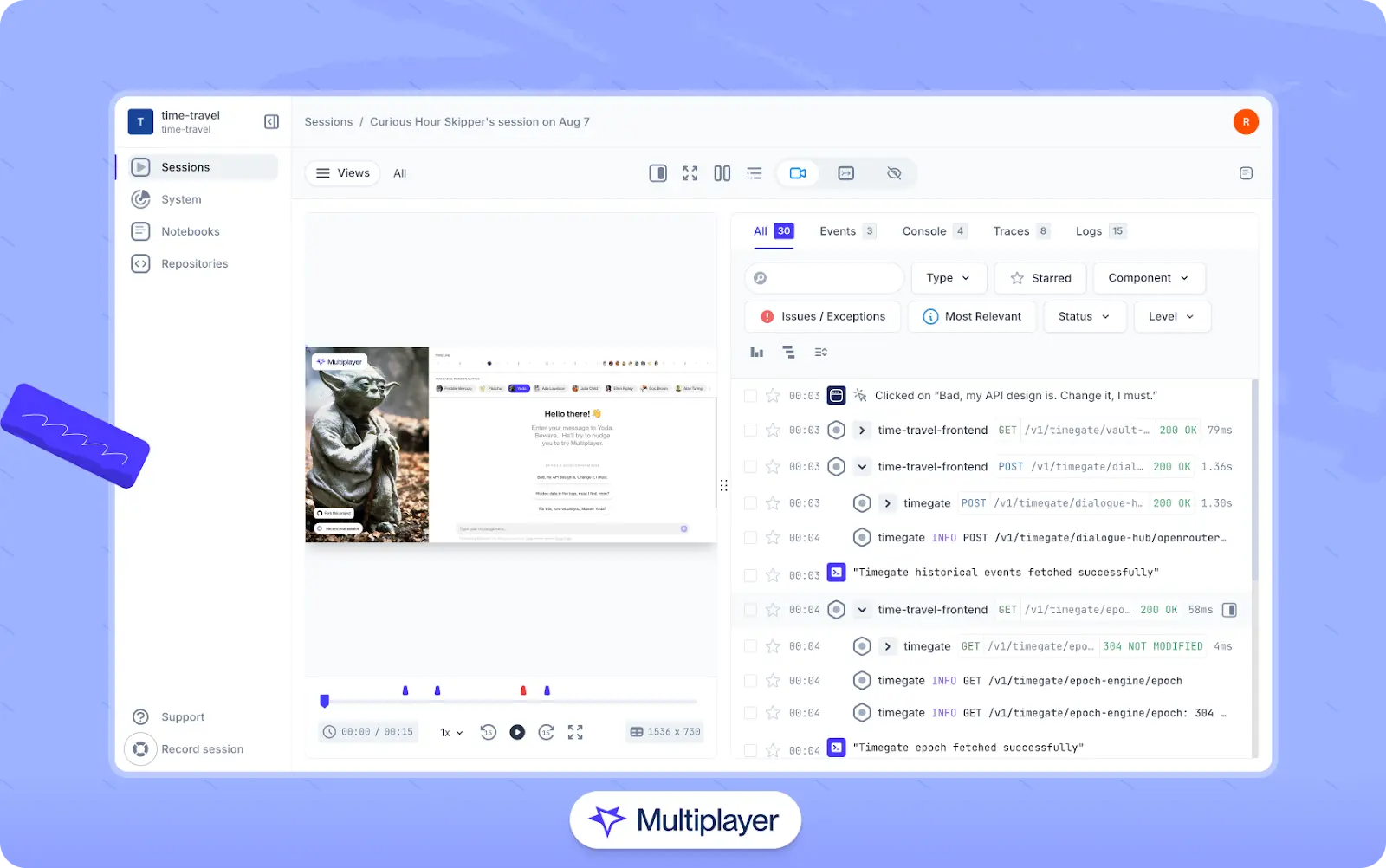
Multiplayer full stack session recordings
Session recordings can also be accessed through Multiplayer’s MCP server, which exposes session context and annotations to connected tools and AI copilots so that their suggestions are grounded in full awareness of what users experienced and how the system responded.
Measure success rigorously
Tracking an IDP's success helps identify what is working, what needs improvement, and whether the investment in platform engineering is justified. Without clear metrics, it is difficult to determine whether the IDP is actually improving developer workflows or simply adding another layer of abstraction.
One key metric is developer productivity, specifically, how much faster teams can move from code to production. This can be tracked using deployment frequency, lead time for changes, and time to onboard new developers. A successful IDP should also result in fewer handoffs between teams, which can be measured by tracking the number of tickets or requests developers need to submit for infrastructure changes.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEEqually important are metrics that reflect platform reliability and developer satisfaction. Measuring the uptime and error rates of pipelines and services managed by the IDP offers insight into the platform's stability.
Platform adoption rate is another vital indicator—if developers bypass the IDP or maintain shadow infrastructure, it signals usability issues. Periodic developer satisfaction surveys, combined with usage analytics, can highlight areas for improvement and validate whether the IDP is truly reducing cognitive load. Ultimately, success is reflected in a balance of quantitative performance metrics and qualitative feedback that demonstrate that the platform is enabling teams to deliver secure, reliable software with less friction.
Parting thoughts
Platform engineering and DevOps are not opposing forces but complementary approaches that, when combined effectively, can drive efficiency, scalability, and innovation in software development. DevOps fosters collaboration, automation, and agility, while platform engineering provides structured self-service tools that empower teams to work more efficiently. Organizations should evaluate their needs and choose the right approach based on their current challenges, whether that's prioritizing cultural transformation with DevOps, adopting platform engineering for a greater degree of standardization, or integrating both practices to create a streamlined, scalable, and sustainable development environment.