Guide
API Architecture: Tutorial & Examples
Table of Contents
API architecture is the design and structure of a software system's APIs (application programming interfaces). An effective API architecture facilitates efficient communication between components, services, and external clients by providing intuitive, maintainable APIs that perform well under varying loads.
Designing API architectures involves careful planning to define endpoints, data formats, protocols, security measures, scalability strategies, and error-handling mechanisms that align with the system's goals. Developers may employ different architecture styles tailored to specific use cases, such as RESTful endpoints for standardized communication, GraphQL for flexible queries, or gRPC for high-performance or real-time use cases.
This article explores the key principles of API architecture, explains five essential API architecture components, and highlights best practices for designing APIs that are maintainable and secure. It outlines key strategies to help you design APIs that are resilient, easy to manage, and capable of meeting modern demands.
Summary of key API architecture concepts
The table below summarizes the three core API architecture concepts this article will explore.
| Concept | Description |
|---|---|
| API architecture components | Foundational components of API architectures include well-defined endpoints, a structured request and response model, middleware functions, authentication and authorization mechanisms, monitoring, and logging. |
| API architecture styles | APIs use one or many communication protocols with unique characteristics and use cases. Modern protocols include REST, gRPC, GraphQL, and WebSocket. |
| API architecture best practices | Key practices include implementing versioning for backward compatibility, maintaining consistent naming conventions, logically grouping resources, emphasizing robust security, crafting comprehensive documentation, and testing thoroughly. |
Five essential API architecture components
Building robust APIs requires carefully designing foundational components to ensure functionality, reliability, and scalability. Let’s take a look at five of these components.
Endpoints
Endpoints allow clients to interact with the API. They define the specific URLs clients use to send HTTP requests (e.g., GET, POST, PUT, DELETE) and receive responses.
RESTful best practices dictate that endpoints to perform operations on a collection of items should be named as plural nouns (e.g., /users, /posts, etc.). API clients should use HTTP methods to indicate actions performed on the resource instead of including verbs in the endpoint name. For example, the endpoint to create a user resource should be POST /users as opposed to POST /createUser.
The table below illustrates five RESTful endpoints for an endpoint that manages user resources.
| Request method | Endpoint | Functionality |
|---|---|---|
| GET | /users | List all users |
| GET | /users/{id} | Get a specific user by ID |
| POST | /users | Create a new user |
| PATCH | /users/{id} | Update a specific user by ID |
| DELETE | /users/{id} | Delete a specific user by ID |
Request/response model
The request/response model is the fundamental interaction paradigm in client-server communication. In this model, each time the client sends a request to the server, the server processes the request and returns a response. The request/response model also defines how data is sent to and received from the server (e.g., in formats like JSON or protocol buffers).
When making a request, the client typically includes the following information:
- The type of request (e.g., GET, POST, PUT, DELETE in HTTP)
- The URL or endpoint of the resource being requested
- Headers containing additional metadata (e.g.,
Authorization,Content-Type) - A body, if necessary (for example, in POST or PUT requests), to send data to the server)
The server processes the request, performs the necessary operations (e.g., retrieving or saving data), and returns a response to the client. The response typically includes:
- A status code (e.g., 200 OK for success, 404 Not Found for an error)
- Headers with additional information (e.g.,
Content-Type,Set-Cookie) - A body containing the requested data or a result message
A common way to document request and response formats is to utilize OpenAPI specifications. For example, the OpenAPI specification below defines the endpoint, request body, response formats, and status codes for a RESTful POST /users endpoint.
openapi: 3.0.3
info:
title: User Management API
description: A simple API for managing users.
version: 1.0.0
paths:
/users:
post:
summary: Create a new user
operationId: createUser
requestBody:
required: true
content:
application/json:
schema:
type: object
required:
- name
- email
properties:
name:
type: string
example: Alice Johnson
email:
type: string
example: alice@example.com
responses:
'201':
description: User created successfully
content:
application/json:
schema:
type: object
properties:
id:
type: integer
example: 3
name:
type: string
example: Alice Johnson
email:
type: string
example: alice@example.com
'400':
description: Invalid input
'500':
description: Internal server errorAs you can see, the specification precisely defines the API’s behavior, including information on endpoints, request and response bodies, data types, and HTTP status codes. Doing so removes ambiguity around the API’s functionality and makes it easy for developers to build, maintain, or consume the API.
Middleware
Middleware is an intermediary layer that facilitates communication between API components. It commonly handles cross-cutting concerns like authentication, logging, or request/response validation. To ensure modularity and follow the single-responsibility principle, middleware functions should be single-purpose to maximize developers’ ability to chain them together and reuse them in different application areas.
For example, API implementations often apply rate limiting by defining a middleware to run within an API Gateway:
const rateLimit = require('express-rate-limit');
const apiLimiter = rateLimit({
windowMs: 15 * 60 * 1000, // 15 minutes
max: 100, // Limit each IP to 100 requests per windowMs
message: 'Too many requests from this IP, please try again later',
});Such a function can be added to various routes to prevent abuse or overloading of the system.
Full-stack session recording
Learn more





Authentication and authorization
Authentication and authorization protect API resources by verifying user identities (authentication) and enforcing access permissions (authorization). APIs commonly use protocols like OAuth 2.0, OpenID Connect, and token-based mechanisms like JWTs to authenticate users. Authorization typically involves implementing Role-Based or Scope-Based Access Control (RBAC/SBAC) to enforce permissions at a granular level.
Authentication and authorization safeguard sensitive endpoints, ensure data privacy, and comply with security standards.
Monitoring and logging
Monitoring and logging both provide visibility into API performance. While these components are often grouped together, it is important to recognize that they are distinct practices that require different tools.
Monitoring, the continuous process of tracking an API's performance, availability, and overall health, involves collecting and analyzing predefined metrics. It involves:
- Collecting metrics like response times, throughput (requests per second), error rates, latency, and resource utilization (CPU, memory, etc.) to track performance
- Detecting downtime to measure system availability
- Tracking user interactions to help teams understand usage patterns and identify potential problems like high request volumes on specific endpoints
Logging refers to recording events and data about API calls, errors, and the system's internal workings. It provides detailed records of events, requests, and errors to assist in diagnostics, debugging, and security analysis.
Four popular API architecture styles
Engineers can utilize different architecture styles to implement the components described in the previous section. Four prominent modern styles include REST, gRPC, WebSocket, and GraphQL, which have largely replaced legacy styles like SOAP, Java RMI, CORBA, or XML-RPC.
As we will see, REST, gRPC, WebSocket, and GraphQL each offer unique benefits and trade-offs. Choosing between them depends on factors like application requirements, performance, scalability, complexity, and developer expertise. Let’s take a closer look at these four architectural styles.
REST API architecture


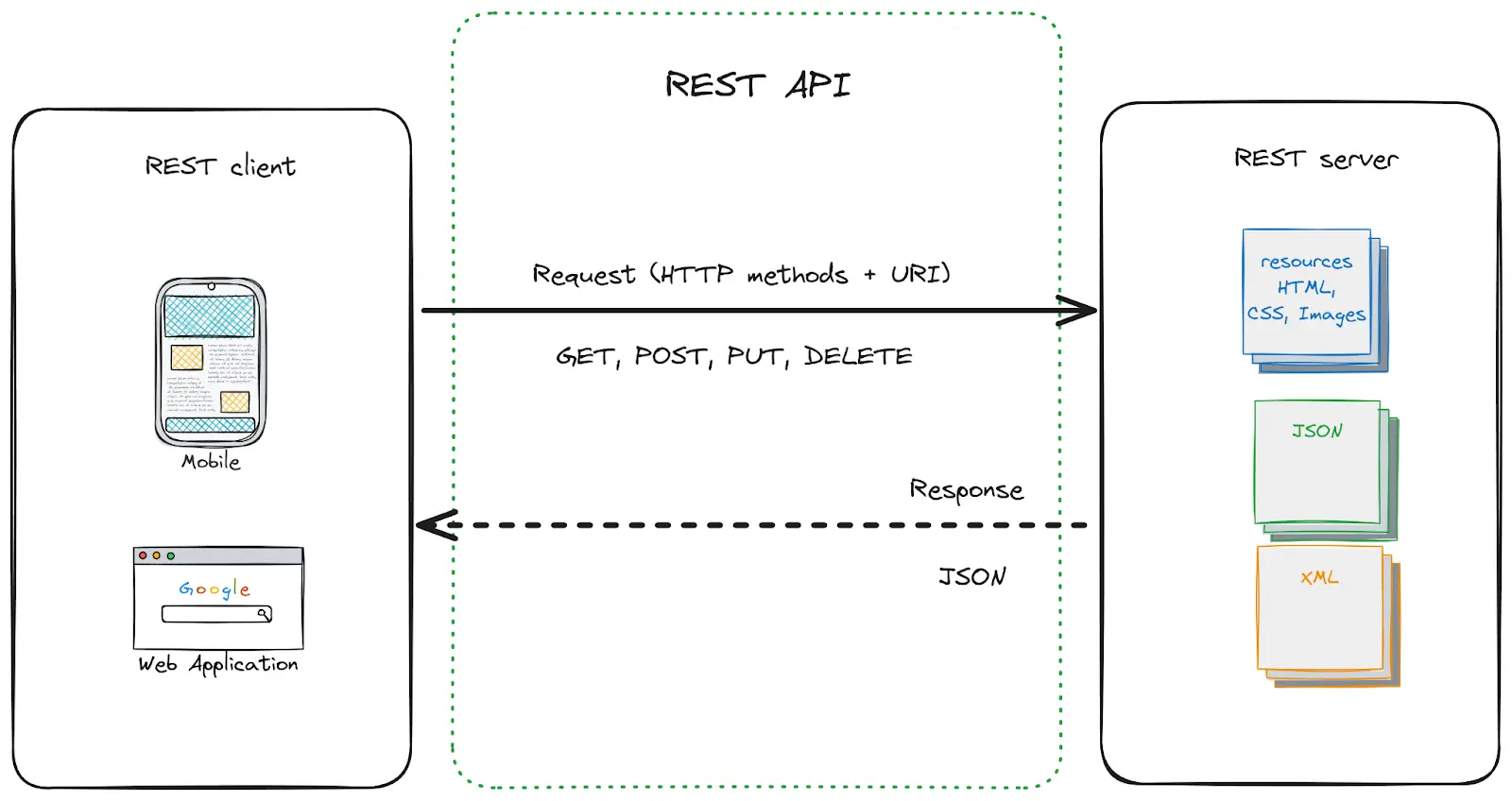
Example of a REST API architecture.
REST (Representational State Transfer) relies on stateless communication and uses standard HTTP methods (GET, POST, PUT, DELETE) to perform CRUD (Create, Read, Update, Delete) operations on resources identified by unique URIs. REST’s simplicity, scalability, and widespread adoption have made it the most popular choice for building APIs since the early to mid-2000s.
When to use REST API architecture
REST is easy to implement, integrates with diverse technologies, and is capable of handling a diverse range of resources. Other advantages of REST include:
- It communicates easily with different clients, such as web browsers, mobile devices, and IoT devices.
- REST has broad support and a vast ecosystem of libraries, tools, and frameworks. This makes it easy to learn, implement, and debug, particularly for teams prioritizing simplicity and rapid development.
- REST utilizes standard HTTP methods and (typically) JSON for data transfer, which means it is compatible with nearly all modern platforms and programming languages.
- REST APIs are highly scalable due to their stateless architecture and separation of concerns between client and server.
However, there are issues with REST that may lead developers to choose alternative styles. For example, because REST communicates using HTTP, every request comes with some inherent overhead (headers, metadata, etc.). For high-performance applications with frequent requests, this overhead can add up.
In addition, REST APIs generally operate at the level of resources (e.g., users, products) rather than providing fine-grained control over specific fields or subresources unless specifically designed to do so. This is not ideal for fine-grained data fetching.
As we will see in the following sections, these limitations have led to the development and adoption of other API architecture styles in different use cases.
gRPC API architecture
gRPC (gRPC remote procedure call) is a high-performance, open-source framework developed by Google that uses HTTP/2 as its transport protocol. It supports multiple languages and enables developers to define service contracts using protocol buffers (protobuf), a compact binary serialization format. gRPC most often facilitates communication between microservices or in other real-time environments, offering advantages like low latency, efficient serialization, and strong type safety.
Here is a sample implementation of a gRPC service.
.proto file: defines the structure of book resources and formats for requests and responses.syntax = "proto3";
package bookservice;
// Message for representing a book
message Book {
string isbn = 1;
string title = 2;
string author = 3;
int32 published_year = 4;
}
// Request to add a new book
message AddBookRequest {
Book book = 1;
}
// Response after adding a book
message AddBookResponse {
bool success = 1;
string message = 2;
}
// The service definition for adding books
service BookService {
rpc AddBook(AddBookRequest) returns (AddBookResponse);
}Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Server code: simulates database transactions by utilizing an in-memory dictionary to store new books.
import grpc
from concurrent import futures
import book_service_pb2
import book_service_pb2_grpc
# In-memory storage for books (acting as our "database")
book_db = {}
class BookService(book_service_pb2_grpc.BookServiceServicer):
def AddBook(self, request, context):
book = request.book
# Check if the book already exists by ISBN
if book.isbn in book_db:
return book_service_pb2.AddBookResponse(success=False, message="Book with this ISBN already exists.")
# Add the book to the "database"
book_db[book.isbn] = book
return book_service_pb2.AddBookResponse(success=True, message="Book added successfully!")
# Start the server
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
book_service_pb2_grpc.add_BookServiceServicer_to_server(BookService(), server)
server.add_insecure_port('[::]:50051')
server.start()
print("Server is running on port 50051...")
server.wait_for_termination()
if __name__ == '__main__':
serve()Client code: creates a connection to the server at localhost:50051 and invokes the add_book function to communicate with the server over a gRPC channel, using Protocol Buffers for message serialization.
import grpc
import book_service_pb2
import book_service_pb2_grpc
# Create a channel to the server
channel = grpc.insecure_channel('localhost:50051')
# Create a stub (client-side object) for the BookService
stub = book_service_pb2_grpc.BookServiceStub(channel)
# Function to add a new book
def add_book(isbn, title, author, year):
book = book_service_pb2.Book(isbn=isbn, title=title, author=author, published_year=year)
response = stub.AddBook(book_service_pb2.AddBookRequest(book=book))
print(response.message)
if __name__ == '__main__':
# Add a new book
add_book("978-1234567890", "The Great Gatsby", "F. Scott Fitzgerald", 1925)When to use gRPC
gRPC is often used in applications demanding high performance, real-time data processing, and bidirectional streaming. The primary benefits of gRPC are that it:
- Avoids the overhead of HTTP requests like headers, metadata, etc.
- Communicates using binary data (via Protocol Buffers), which is largely responsible for gRPC's performance advantages over text-based formats like JSON.
- Provides a language-agnostic mechanism to integrate services written in different programming languages.
However, implementing gRPC is not trivial, and doing so effectively requires a development team with expertise in its concepts and best practices. Many developers lack familiarity with binary protocols like Protocol Buffers. In addition, defining Protocol Buffer schemas adds upfront overhead, and debugging requests can be more challenging since the data is serialized and not human-readable. Finally, gRPC is not natively supported in browsers without a workaround like gRPC-Web, which adds complexity and extra configuration layers.
GraphQL API architecture


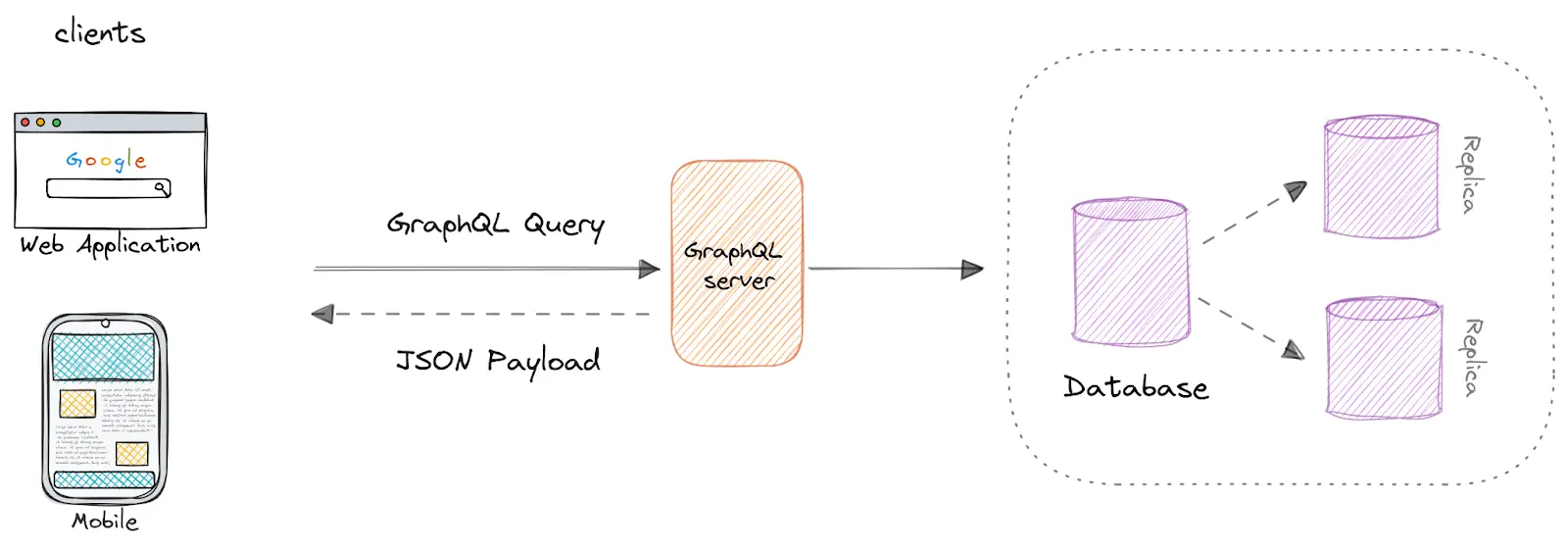
GraphQL API architecture example.
GraphQL is a query language and runtime for APIs originally developed by Facebook. It was designed to provide a flexible and efficient way to interact with data. Unlike REST, where endpoints typically return fixed data structures, GraphQL allows clients to request precisely the data they need to improve performance and flexibility.
GraphQL APIs typically expose a single endpoint (e.g., /graphql) for all operations. GraphQL also requires strongly typed data structures, meaning that each resource must adhere to a predefined schema. The key feature of GraphQL is that it supports hierarchical data querying: GraphQL queries mirror the shape of the data, making it easy to request nested or related data in a single request.
For example, the following query fetches a user’s information and their posts in a single request. Fetching the same data in a REST API would require several client requests and might return additional data fields that are not needed.
{
user(id: 1) {
name
posts {
title
content
comments {
text
author {
name
}
}
}
}
}When to use GraphQL
As shown above, GraphQL is used for its flexibility and efficiency. It reduces data transfer by eliminating overfetching, and it also enables combining data from multiple sources into one response. This makes it ideal for several types of applications:
- Dynamic frontends with diverse data needs - Single-page applications (SPAs) or mobile apps often have different screens or components that require varying subsets of data. Such use cases benefit from GraphQL’s flexibility.
- Applications with complex data relationships - Applications that work with deeply nested or interconnected data (e.g., social networks, e-commerce platforms) benefit from GraphQL’s ability to query nested resources efficiently in a single request.
- Microservices with aggregated data - In a microservices architecture, GraphQL can act as an aggregation layer. It can combine data from multiple services into a unified API and simplify integration for clients.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEGraphQL’s complexity is likely not justified for simple applications. In addition, although GraphQL’s primary benefit is its flexibility and efficiency in fetching nested relational data, this feature is not “free.” GraphQL servers utilize resolver functions to perform several steps under the hood, which can strain backend systems and actually hinder performance if not managed carefully. For example, in the example query above, GraphQL resolvers may need to perform the following steps:
- Query a users database table to get the user’s details.
- Query a posts database or service to get all the posts for that user.
- For each post, query a comments database or service to fetch the comments for each post.
- For each comment, query a users table or service again to get the comment author's name.
Although these steps are abstracted away, they still contribute to the server’s performance overhead.
WebSocket API architecture


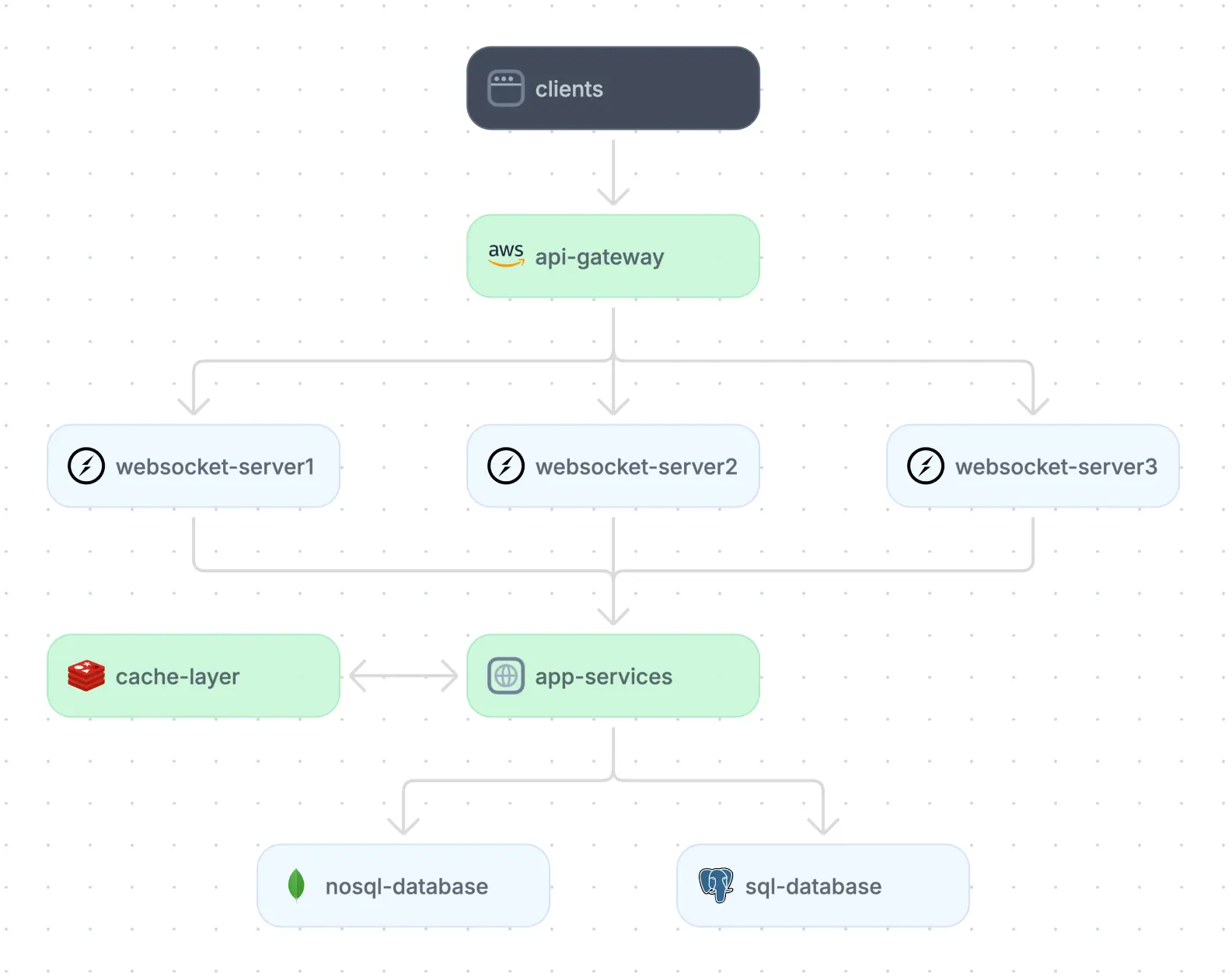
Example of a WebSocket API architecture.
WebSocket is a communication protocol that provides full-duplex, persistent connections between a client and a server over a single TCP connection. Unlike traditional HTTP, where communication is request-response-based, WebSocket allows for continuous two-way communication, making it well-suited for real-time applications.
When to use WebSocket
The WebSocket protocol’s ability to maintain a persistent, bidirectional connection eliminates the overhead of repeated HTTP handshakes. If your application requires low latency, continuous communication, or real-time updates, WebSocket is a natural choice. Examples of such applications include:
- Multiplayer online games, where low latency and real-time synchronization are necessary
- Internet of Things (IoT) systems, where devices need to send and receive data in real time, such as smart home systems or industrial sensors.
- Push notifications, alerts, or updates in dashboards or mobile apps.
However, ensure your infrastructure can handle the load of long-lived connections, especially in high-traffic scenarios. Each WebSocket connection consumes resources (memory, CPU, etc.) on the server, and many servers are limited in the number of open connections they can handle.
In addition, scaling WebSocket connections can be more complex than scaling stateless HTTP and often requires horizontal scaling and load-balancing mechanisms. Because WebSockets are stateful connections, scaling across multiple servers requires state sharing (often using message queues or distributed state management systems), which adds further complexity. For applications with infrequent updates or that do not require two-way communication, using server-side events is likely more efficient than using WebSockets.
Eight API architecture best practices
Now that we have discussed common API architecture styles, let’s explore several key practices to help your team build APIs effectively. For a more in-depth look at API development best practices, check out our free API Development: Best Practices & Examples guide.
Implement versioning
When introducing new features or changes, implement versioning to ensure backward compatibility. Use clear versioning schemes such as /v1/ or /v2/ in endpoints. This approach allows existing clients to continue functioning while giving developers the flexibility to upgrade at their own pace. When introducing breaking changes, create a new version of the API while continuing to support older versions.
An API’s version is often indicated by appending a version number to the base URL.
https://api.example.com/v1/usersDefine resource grouping
Organize related resources logically within the API. For instance, group endpoints dealing with user management under /users and order-related operations under /orders. This logical structure simplifies navigation and enhances the API's intuitiveness. Nest resources only when there is a clear and logical parent-child relationship (e.g., /users/{user_id}/orders).
Deeply nested endpoints can become complex and difficult to maintain. They complicate managing resource relationships, especially when changes or deletions occur. Scalability becomes an issue as expanding or modifying the API can introduce complexity or breaking changes. Additionally, adding new related resources may require significant alterations to the URL structure.
/users/{user_id}/posts/{post_id}/comments/{comment_id}/replies/{reply_id}Note that the increased URL length makes it hard to read and maintain. Consider alternative approaches like using query parameters or returning URLs to related resources.
Validate data
Rigorously validate all incoming request data using data type checks, range constraints, and regular expressions to ensure data integrity and prevent unexpected errors. For example, take a look at the below code snippet:
from pydantic import BaseModel
class UserRequest(BaseModel):
username: str
email: str
class UserResponse(BaseModel):
id: int
username: str
email: str
request_data = {"username": "john_doe", "email": "john.doe@example.com"}
request_user = UserRequest(**request_data)
response_data = {"id": 1, "username": "john_doe", "email": "john.doe@example.com"}
response_user = UserResponse(**response_data)This example demonstrates how the Pydantic library can be used in Python scripts to validate data. By defining UserRequest and UserResponse models, Pydantic ensures that the data received and sent adhere to the expected structure and data types.
Test and debug
Use automated tools to test API endpoints rigorously. Perform functional tests to validate expected behaviors, load tests to ensure performance under various conditions, and security tests to identify vulnerabilities. Continuous testing maintains the API's reliability and performance as it evolves.
When bugs are identified, effective tooling can help teams discover their root cause and resolve them more quickly. For example, Multiplayer’s full stack session recordings allow teams and users to capture complete session recordings of unexpected behavior. These recordings include frontend screens and data from backend services, such as traces, metrics, logs, and request/response content and headers. Recordings can be easily shared across development teams to streamline communication, and they can also be used as inputs to AI coding tools to provide context for more accurate fixes, tests, and features.


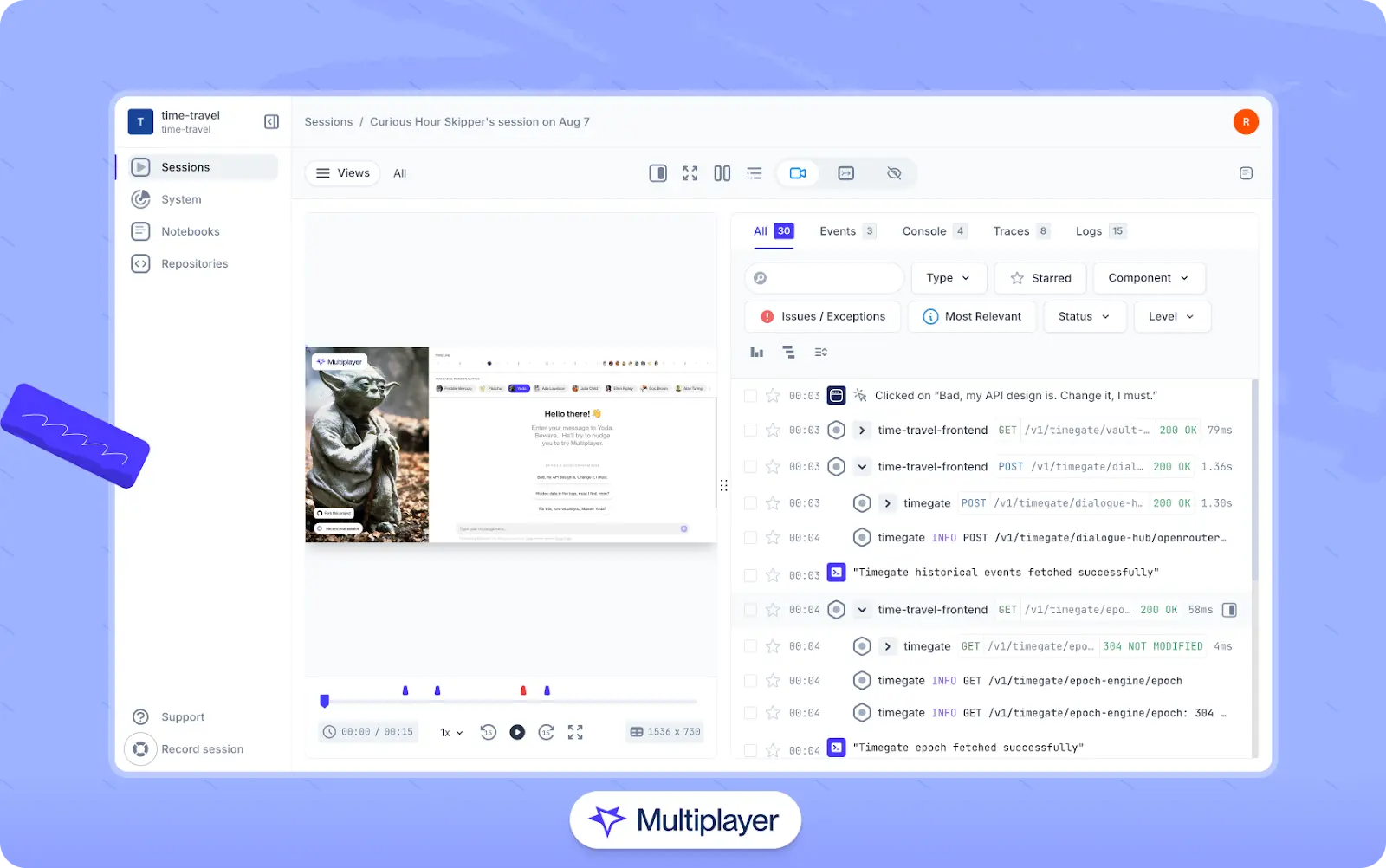
Multiplayer’s full stack session recordings
Ensure strong security controls are in place
Implement robust authentication and authorization mechanisms to protect sensitive information. OAuth 2.0 and JSON Web Tokens (JWT) are widely adopted to ensure secure access. Additionally, encrypt data in transit using HTTPS and enforce proper access controls to safeguard against unauthorized actions.
Account for error handling
Implement robust error-handling mechanisms to gracefully handle invalid requests, unexpected conditions, and server-side issues. Return meaningful error responses with clear error codes and descriptive messages. When crafting error responses, pay attention and do not disclose sensitive information that might expose security vulnerabilities or violate user privacy. Examples of information that should not be included in error responses include implementation details, stack traces, and personal user information (full names, contact information, account numbers, credit card digits, IP addresses, etc.).
Document APIs thoroughly
Provide comprehensive, detailed documentation covering all API endpoints, including request/response examples and usage instructions. Ensure documentation is updated whenever architectural changes occur, as clear, accurate documentation empowers developers to integrate and debug efficiently.
For teams managing complex, distributed systems, Multiplayer offers advanced features to automatically document APIs and their underlying architectures without the need for external API clients or manual scripting. Two of these features include:
- Notebooks, which allow developers to document API integrations with API calls, executable code blocks, and step-by-step instructions for executing and debugging APIs.
- System dashboard, which leverages OpenTelemetry to automatically track changes to APIs, dependencies, and the overall system architecture. This ensures your documentation stays accurate and up-to-date, reducing maintenance overhead and preventing architectural drift.

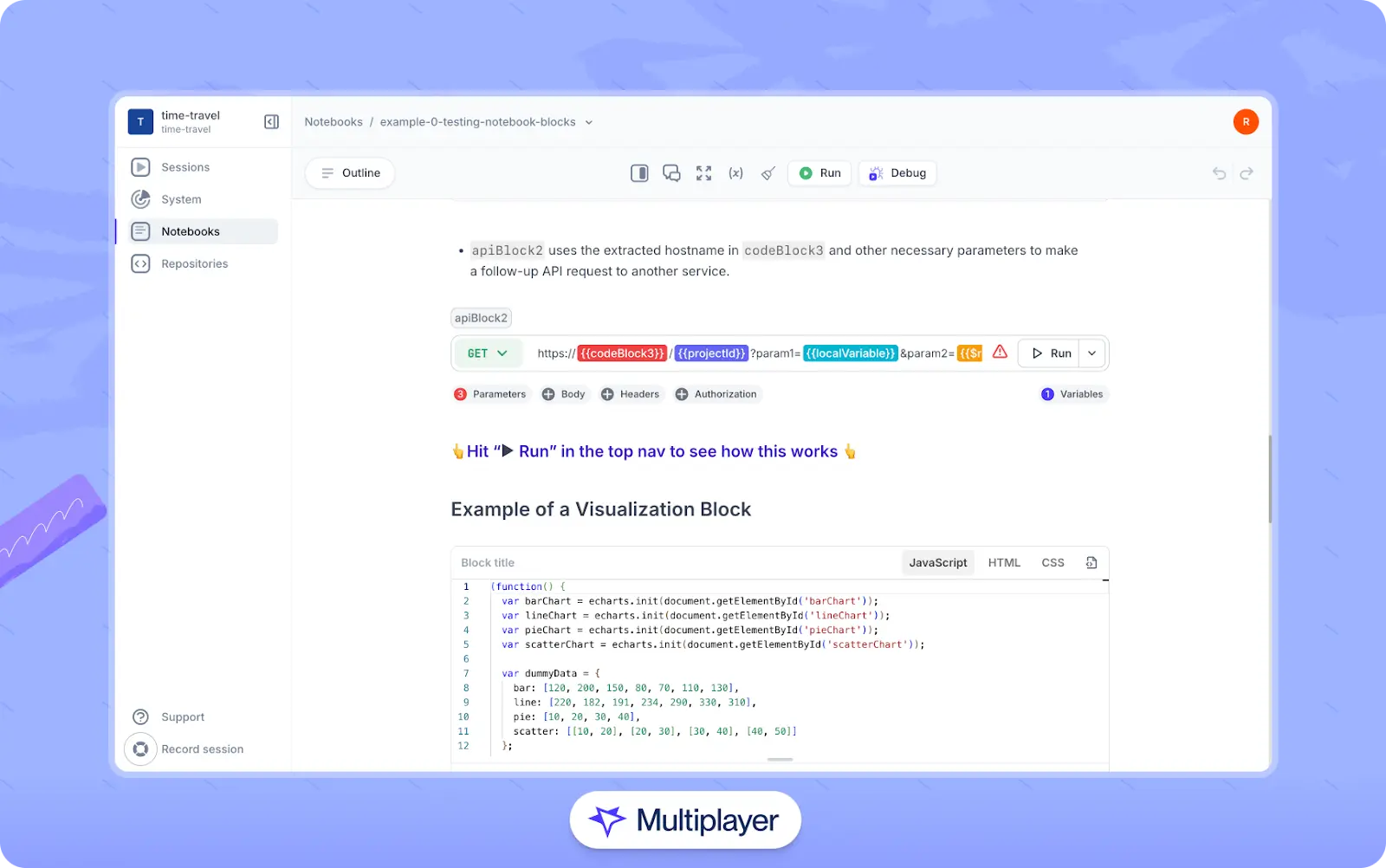
Multiplayer notebooks
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEConclusion
Effective API architecture balances robust design, security, and usability to ensure seamless communication and system reliability. Key components like endpoints, authentication, and error handling form the backbone, while protocols like REST and gRPC cater to diverse use cases. Adopting best practices such as versioning, consistent naming, and thorough testing ensures scalability and adaptability. By focusing on these principles, teams can build APIs that are efficient, secure, and future-proof.