How to evolve your tech stack to leverage LLMs in 2025
Depending on your specific use case, your approach to LLMs may vary. Here’s a breakdown of the options and best practices.

(updated on Dec 3rd, 2025)
Although the tech industry is conflicted about AI, everyone can agree on one thing: generative AI is a generational change that will affect every industry.
To remain competitive companies will need to evolve their products and services to leverage or include AI-powered features along with their existing offerings.
While, this fundamental question remains, the technology landscape in 2025 has matured significantly since the initial LLM boom of 2023, and the answers have become more nuanced, practical, and focused on solving real problems rather than chasing hype.
In the particular, the path forward depends heavily on your specific use case, the criticality of the AI feature, and your available resources.
The 2025 LLM landscape: what's changed
The LLM ecosystem has evolved dramatically. OpenAI announced GPT-5 as its latest flagship model, representing a significant leap in intelligence, while open-source alternatives like DeepSeek V3.2 and have emerged with powerful capabilities and permissive licensing.
Perhaps most significantly, the quality gap between open-source and proprietary models has narrowed considerably, with open models like LLaMA 3, Gemma, and Mistral 3 catering to varied enterprise needs from multilingual support to reasoning and multimodal tasks.
The maturation of the ecosystem means you have more viable options than ever, but also more complexity in choosing the right approach.
SaaS LLM provider or OSS LLM?
Let’s say that you’re building a new product that involves human interaction through natural language and you need to leverage LLMs (Large Language Models). This is a mission-critical product that is pivotal to your whole company strategy where time-to-market is less important than obtaining a specific, high-quality output and maintaining complete control over proprietary data and trade secrets.
In that case, you’ll want to consider developing and refining an LLM in-house, which will mean making a significant investment in computational resources, data, and AI expertise.
However, let’s say that you’re adding a feature to an existing platform that will enhance the user experience but may not be the most critical element. You also want to ship asap, maybe before a competitor or to capitalize on a market trend. In that case, you may want to select a third-party provider that already offers an off-the-shelf, pre-trained, LLM as a SaaS solution.
Based on your specific use case, you'll want to consider these pros and cons:
Using a SaaS LLM provider
If you're adding an AI feature to enhance user experience but it's not mission-critical, and you want to ship quickly, third-party providers remain the fastest path forward.
PROS:
- Quick deployment with pre-trained models that are production-ready
- Consistent system upgrades as providers continuously improve their models
- Scalability leveraging the provider's infrastructure and expertise
- Cost effective with pay-per-use pricing that scales with usage
CONS:
- Limited control & customization over model behavior and capabilities
- Vendor dependency on the provider's availability, pricing changes, and feature roadmap
- Data privacy concerns depending on your industry and compliance requirements
Examples: OpenAI (GPT-5), Anthropic (Claude), Google (Gemini 2.5)
Self-hosted with SaaS LLM API integration
You integrate with a provider's API but host your application logic, giving you more control over the user experience while delegating model management to the provider.
PROS:
- Rapid development without managing model infrastructure
- Customization of your application logic and user-facing features
- Scalability through the provider's infrastructure
- Flexible cost structure though you'll incur costs for API calls plus your hosting infrastructure
CONS:
- Skill requirements for effective prompt engineering and integration
- Still vendor-dependent on the provider's availability and pricing
- Potential latency from external API calls, especially for real-time applications
Self-hosted with open-source LLM
The open-source landscape in 2025 offers unprecedented options. Models like DeepSeek R1 excel in logical inference and mathematical problem-solving, while Qwen2.5-72B provides strong multilingual support and structured output generation.
PROS:
- Full control over deployment, fine-tuning, and integration
- Flexibility & customization to tailor models for domain-specific needs
- Data privacy with complete control over where data is processed
- Cost effective for high-volume usage (after initial infrastructure investment)
- Community support and rapid innovation from the open-source ecosystem
CONS:
- Resource intensive requiring significant expertise, compute resources, and ongoing maintenance
- Infrastructure complexity in deploying and scaling models in production
- Model selection challenge with over 2 million public models on Hugging Face and new releases weekly
- Quality variability as not all open-source models are enterprise-ready
Examples: LLaMA 4, DeepSeek V3, Qwen 2.5, Mistral Large
Self-hosted, built in-house LLM
Building your own LLM from scratch remains the most resource-intensive option and is typically only justified for companies with unique requirements and substantial resources.
PROS:
- Full ownership over the entire development lifecycle, ensuring complete data privacy and control
- Tailored solutions specifically designed for your product's unique requirements
- Long-term flexibility to evolve the model alongside your product
CONS:
- Extremely resource & cost intensive (training costs can exceed millions of dollars)
- Extensive expertise requirements in ML engineering, infrastructure, and model training
- Multi-year timeline from conception to production deployment
The estimated costs for training large models remain substantial—though the specific numbers have changed, the order of magnitude investment required hasn't.
Evolving your tech stack for AI in 2025
Adding LLMs to your existing software means reviewing and evolving your entire stack: infrastructure, data management, observability, security, and development workflows.
(1) Architect for continuous evolution
The AI landscape changes even more rapidly than traditional software. Frameworks like LangChain and LlamaIndex have transformed how developers integrate and query data, while tools like vLLM and Haystack set new benchmarks for speed and scalability.
When integrating LLMs into your product, architect for change:
- Model flexibility: Design your system to support multiple models and embeddings simultaneously. The "best" model for your use case may change quarterly as new releases emerge. Build abstraction layers that allow you to swap models without rewriting application logic.
- Prompt Management: Separate prompts from code so you can iterate on them independently. What works well today may need refinement as models evolve or as you gather user feedback. Consider using prompt management tools that enable A/B testing and version control.
- Context Window Optimization: Modern models support context windows up to 128K tokens, enabling more sophisticated prompt engineering and reducing the need for fine-tuning in some cases. Design your data pipelines to take advantage of larger context windows when beneficial.
- Embeddings Strategy: Plan for embedding model updates. As new embedding models emerge with better semantic understanding, you'll want the flexibility to regenerate embeddings without major architectural changes.
(2) Prioritize observability and debugging
One of the most critical, and often overlooked, aspects of integrating LLMs is building robust observability into your system from day one.
AI debugging tools improved problem-solving rates from 4.4% in 2023 to 69.1% in 2025, but this improvement comes from purposeful investment in the right tooling and practices.
Why LLM debugging is uniquely challenging:
Unlike traditional software where errors are deterministic, LLM behavior is probabilistic. The same prompt can generate different responses, making reproducibility difficult. Hallucinations are common yet hard to detect automatically. Performance can degrade subtly over time as user patterns shift or as you modify prompts.
Key observability practices:
- Comprehensive logging: Capture not just the final LLM output, but the complete context: user input, system prompts, retrieved context (in RAG applications), model parameters, latency, token usage, and any errors. This complete picture is essential for debugging issues that only manifest in production.
- Prompt versioning: Track which prompt version generated each response. When you discover an issue, you need to know whether it affects only the latest prompt iteration or is systemic across versions.
- Performance monitoring: Track latency, token usage, and cost per request. LLM costs can spiral quickly if not monitored closely. Set up alerts for anomalies in these metrics.
- Quality evaluation: Implement automated evaluation of LLM outputs where possible. For customer-facing features, consider human-in-the-loop review processes, especially during initial rollout.
- Session-based context: For applications where LLMs interact with your broader system (especially debugging or support workflows), maintain session-based context that correlates LLM interactions with user actions, backend traces, and system state. This holistic view is critical for understanding failures in complex distributed systems.
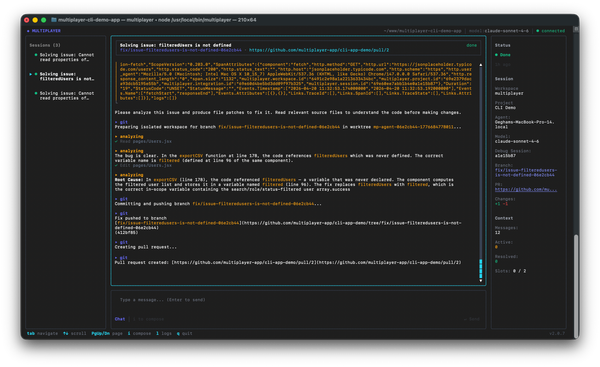
The debugging use case: a practical example
Let's examine a concrete example that illustrates why thoughtful LLM integration matters: using AI coding tools to assist with debugging distributed systems.
The Challenge: Debugging distributed systems is notoriously difficult. Issues span multiple services, manifest inconsistently, and require correlating data from numerous sources: frontend errors, backend traces, database queries, logs, and user actions.
The naive approach: Simply giving an LLM access to log files or error messages produces mediocre results. The model lacks crucial context: What was the user trying to do? What services were involved? What was the state of the system? Without this context, even the most advanced LLM can only make generic suggestions.
The effective approach: Provide the LLM with comprehensive, correlated data captured at the session level: everything that happened in a specific user journey from frontend interactions through backend services. With this complete context, the LLM can:
- Suggest specific root causes based on the actual sequence of events
- Recommend targeted fixes based on what actually failed, not just generic solutions
- Generate clear explanations for different stakeholders (technical for engineers, plain language for support)
This example highlights a critical insight: the quality of LLM outputs depends entirely on the quality and completeness of data you provide as context.
This principle extends beyond debugging to any LLM application. Whether you're building RAG systems, code assistants, or customer support tools, investing in capturing and structuring the right data is as important as choosing the right model.
One copy/paste in your terminal and the debugging agent is running:
npm install -g @multiplayer-app/cli && multiplayer
Rather explore first?👇