Automatically create test scripts from a full stack session recording
Turn a full stack session recording into a reproducible test script. It’s like getting a unit test written by the bug itself. Minus the guesswork, setup, and manual scripting.


With one click, Multiplayer now turns full stack session recordings into test scripts that capture:
- Every API call, payload, and header
- The exact sequence that triggered the failure
- A live, editable notebook your team can run, test, and verify
Distributed debugging stages
"Debugging" is often used as a broad umbrella term. It covers everything from realizing something's broken to confirming it's fixed. But when engineers talk about debugging as a process, they often break it into stages. Especially when thinking about complex, distributed systems.
Here’s how engineers typically break it down:
- Detection - “Something’s wrong.”
You spot an alert, error message, customer support ticket, unexpected behavior, or test failure. You know there’s a problem, but not much more.
- Root Cause Analysis - “Why is this happening?”
This is often the hardest part of debugging, because you need to find what’s actually broken (the “what”, “when”, “why” and ”how”), not just the symptom.
In distributed systems, it gets tricky fast: logs, traces, metrics, recent deployments, and tribal knowledge must all be pieced together. Issues can span services, teams, or even regions, and the point of failure is rarely where the symptoms show up.
- Reproduction - “Can I trigger this reliably?”
Before you can fix a bug, you need to understand it. And that often means reproducing it.
But distributed systems introduce complexity: timing issues, race conditions, and load-sensitive behaviors can make bugs intermittent and hard to isolate. Reproduction may require mocks, test harnesses, or simulated environments that reflect the exact state of the system at the time of failure.
- Resolution - “Let’s fix it.”
Finding a fix is often a trial and error approach and might require coordination across multiple service owners. Fixes can span application logic, infrastructure, deployment configs, or third-party systems.
Given that issues in distributed systems are often caused by multiple root causes coming together as a perfect, unpredictable storm, developers need to have full visibility of how any change will affect the overall systems and all downstream dependencies. One change in a service can affect dozens of others.
- Verification - “Did we fix it?”
Once fixed, you need to make sure it stays fixed.
This often means replaying the scenario, running regression tests, and monitoring closely to ensure nothing else broke along the way. In distributed systems it’s a continuous process of validation under real-world conditions.
Common downsides in traditional bug reproduction and resolution
Uncovering the root cause of an issue in distributed systems can be challenging. But even after detection, developers often face major roadblocks during reproduction and resolution:
- Test bias and incomplete coverage: Engineers naturally write tests based on assumptions or imagined failure paths. This often misses real-world bugs, especially those triggered by edge cases or unpredictable system behavior.
- High maintenance cost: As products evolve, test scripts quickly become outdated or time-consuming to write manually. Keeping them current consumes time that could be better spent on development or testing itself.
- Hard-to-reproduce bugs: Some failures rely on specific timing, state, or data conditions that are hard to replicate outside of production.
- Poor collaboration and visibility: Reproduction steps are often buried in Slack threads, untracked documents, or someone’s local setup; slowing down teamwork and increasing risk.
- Retroactive test creation is hard: After fixing a bug creating a useful test from memory is time-consuming and often misses critical context.
- Limited protection against regressions: Without accurate, reproducible tests tied to past bugs, it’s easy to accidentally reintroduce issues during future changes.
The result? With traditional approaches, engineering teams are forced to weigh the time and effort to build a test script against the time it takes to manually verify the bug, factoring in not just engineering hours, but lost momentum and opportunity cost.
Auto-generated, runnable test scripts
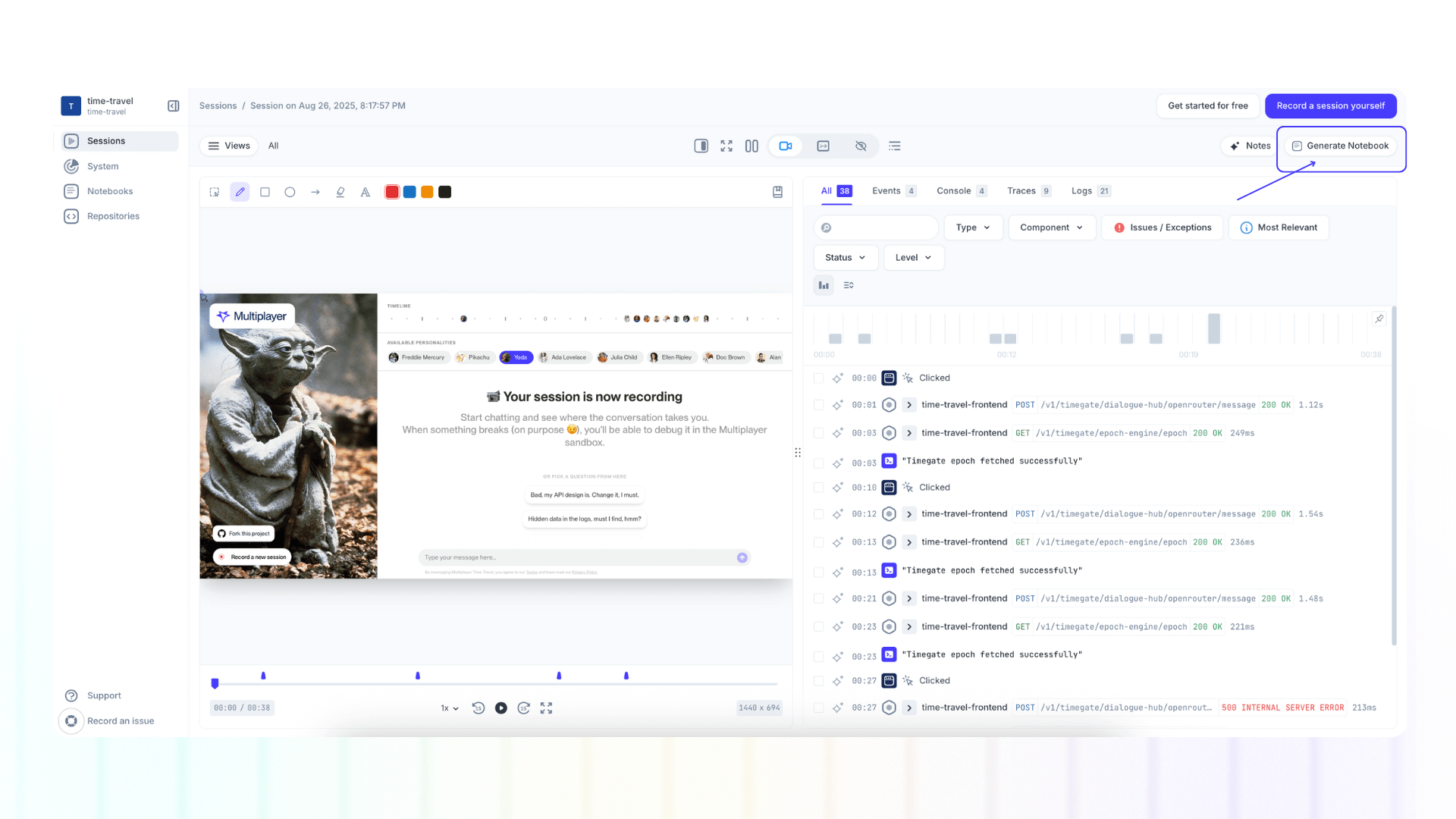
Multiplayer’s full stack session recordings allow developers to quickly and accurately identify the root cause(s). They capture everything you need to understand a bug, from frontend screens, backend traces, logs, full request/response content and headers. All in a single, sharable and annotatable timeline.
But that’s only half the equation: now they have to reproduce it and resolve it.
That’s why we’re introducing the ability to generate a notebook directly from a deep session replay of your bug. This auto-generates a runnable test script (complete with real API calls, payloads, and code logic) that mirrors the failure path.
This bridges the gap between observation and action.
With this release, developers can:
- Reproduce issues effortlessly: Notebooks capture the exact sequence of API calls, headers, edge-case logic, and system behavior that led to the bug, making it easy to simulate and understand the issue.
- Collaborate with full context: Share a complete, interactive snapshot of the bug. No more guessing, re-explaining, or syncing across tools. Everyone immediately understands the problem and can test it themselves.
- Verify fixes immediately: Modify API or code blocks to test potential fixes. Re-run the Notebook to confirm your patch resolves the bug before shipping. It acts like a unit or integration test, but targeted to the exact failure path.
- Document real behavior: Use Notebooks to record how systems actually behave in production, including edge cases and unexpected flows. Great for onboarding, audits, or future reference.
- Prevent regressions: Re-run the Notebook after code changes to ensure the bug stays fixed. It acts like a custom, high-fidelity regression test, built straight from the incident.
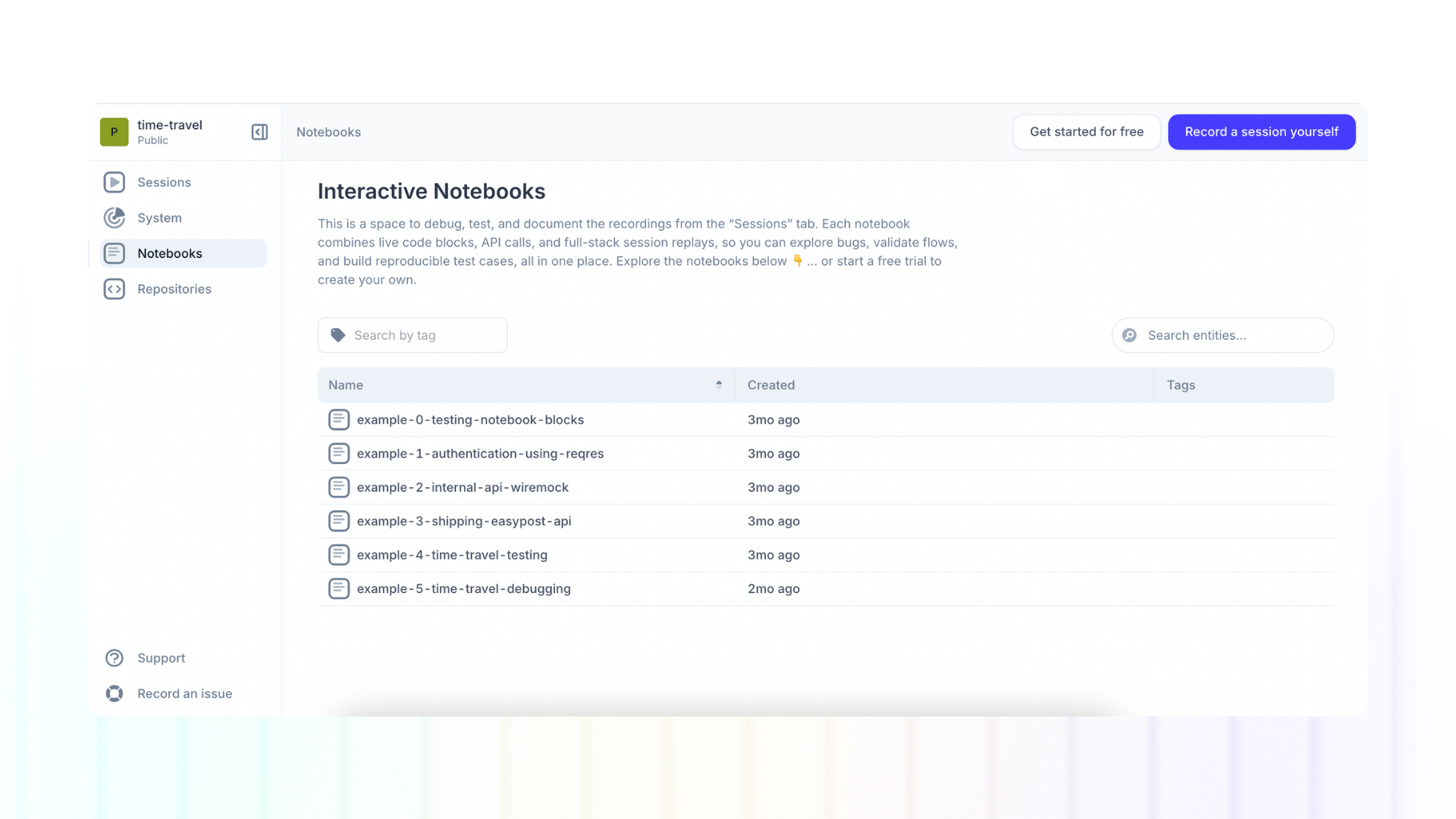
Sandbox notebook examples
The best way to understand how notebooks work, is to see practical examples. So here are some notebooks you can explore in our free sandbox:
- example-0-testing-notebook-blocks: Overview of all the text / API / code / visual blocks supported in notebooks
- example-1-authentication-using-reqres: An example notebook using reqres API
- example-2-internal-api-wiremock: An example notebook of an internal API mocked using WireMock
- example-3-shipping-easypost-api: An example notebook using EasyPost API
- example-4-time-travel-testing: An example notebook of a testing spec document for the Multiplayer’s "Time travel" demo app, which feeds data into this sandbox project
- example-5-time-travel-debugging: An example of a test script automatically generated from a full stack session recording of the Multiplayer’s "Time travel" demo app
By checking the last example, you'll see how auto-generated test scripts help eliminate:
- Guesswork in reproducing bugs
- Time spent building brittle test environments
- Gaps in communication and handoffs
- The risk of forgetting what actually happened
They don’t just help you fix the bug, they leave you with a runnable, verifiable notebook that prevents it from coming back.
One copy/paste in your terminal and the debugging agent is running:
npm install -g @multiplayer-app/cli && multiplayer
Rather explore first?👇