Guide
API Integration: Best Practices & Examples
Table of Contents
APIs (Application Programming Interfaces) connect modern software systems and enable the exchange of data and functionality between applications, services, and platforms. API integration refers to the strategic design and implementation of these connections through internal and external APIs.
This article dives into the best practices for secure, performant, and scalable API integrations. It covers strategies for developing new integrations and managing existing ones effectively. API consumers will learn to assess their integration environment and design resilient and fault-tolerant API calls. API producers can explore how to create secure API integrations that handle requests efficiently and manage versioning for long-term maintainability.
Summary of key API integration best practices
The table below summarizes the critical best practices for API producers and consumers.
| Best practices | Description |
|---|---|
| Optimize API request handling and performance | Reduce latency with caching, batch requests, and pagination. Optimize queries, monitor performance, and use asynchronous processing. |
| Secure API communications | Use OAuth2, API keys, or JWT for authentication. Encrypt data, validate requests, enforce RBAC, and conduct regular security audits. |
| Implement API versioning and compatibility | Use semantic API versioning and maintain multiple API versions to give clients time to adapt to new features. |
| Sunset outdated API versions | Phase out outdated APIs gradually and provide deprecation notices through written documentation, notifications, and HTTP headers. |
| Provide integration guides for developers | Help developers adopt your API by offering hands-on integration guides with real-world examples, executable code blocks, and debugging tools. |
| Design resilient and fault-tolerant API calls | Implement retries with exponential backoff, use circuit breakers, and apply graceful degradation strategies. |
| Understand your integration environment | Map data flow between services, analyze API dependencies, and identify failure points in the data pipeline. |
API integration best practices for API providers
API producers are responsible for designing and maintaining reliable, scalable APIs that are easy for others to integrate with. This requires a balance of
- Strong internal development practices, such as securing endpoints and optimizing performance, and
- Consumer-facing strategies like clear interface design, comprehensive documentation, and thoughtful versioning and deprecation.
In this section, we’ll explore best practices for each of these areas.
Optimize API request handling and performance
An inefficient API slows application workflows, increases infrastructure costs, and frustrates users. Minimizing latency is essential for smooth integration. Some suggestions:
Implement caching strategies
Caching stores frequently accessed data, reducing the need for repetitive API calls. Implementing caching at multiple levels, i.e., server-side, client-side, and within API responses, helps minimize load and accelerate response times.
You can implement server-side caching by using Redis or Memcached to store computed API responses. This reduces database lookups.
import redis
from fastapi import FastAPI
app = FastAPI()
cache = redis.Redis(host='localhost', port=6379, decode_responses=True)
@app.get("/data")
async def get_data():
cached_data = cache.get("key:data")
if cached_data:
return {"data": cached_data}
data = fetch_from_database()
cache.setex("key:data", 300, data)
return {"data": data}For HTTP caching, use Cache-Control, ETag, and Expires headers to instruct clients and proxies on caching behavior, reducing unnecessary requests.
Client-side caching can be implemented by storing API responses in browser storage (e.g., IndexedDB, LocalStorage) when appropriate.
Minimize network overhead with batch processing
Multiple small API calls introduce unnecessary overheads and slow down performance. Instead, batch processing consolidates various requests into a single call, reducing the number of round-trips between the client and server. Batch API endpoints to allow clients to send multiple requests in a single payload. Example:
{
"requests": [
{ "method": "GET", "path": "/users/1" },
{ "method": "GET", "path": "/users/2" }
]
}Instead of updating records one at a time, process multiple updates in a single transaction to reduce database load.
While not a batch processing technique per se, GraphQL can also reduce the need for batching by allowing clients to retrieve multiple related resources in one structured query.
Limit response size
Large response payloads increase bandwidth usage and slow down API responses. To improve efficiency:
- Use offset-based or cursor-based pagination to serve data in manageable chunks instead of returning thousands of records.
- Allow filtering by relevant parameters (e.g.
/users?status=active,) to return only the required data.
Utilize asynchronous processing for long-running tasks
Blocking API requests with time-consuming operations (e.g., sending emails, processing large datasets) degrades performance. Instead, APIs should offload these tasks using asynchronous processing.
For example, the code below utilizes Celery, a distributed task queue, to send emails asynchronously. It configures Celery to use Redis as the message broker and result backend. The send_email function validates the recipient’s email address and then calls a separate function to send the email. The email-sending process can run in the background without blocking the main application.
from celery import Celery
from services.email import send_email_smtp
import os
app = Celery(
'tasks',
broker=os.getenv('CELERY_BROKER_URL', 'redis://localhost:6379/0'),
backend=os.getenv('CELERY_RESULT_BACKEND', 'redis://localhost:6379/1')
)
@app.task(name='tasks.send_email')
def send_email(to: str, subject: str, body: str):
if not to or '@' not in to:
raise ValueError("Invalid recipient address")
send_email_smtp(to=to, subject=subject, body=body)
return f"Email sent to {to}"Secure API communications
Modern APIs are frequent targets for attackers because they often expose sensitive data and serve as direct entry points into critical systems. A single insecure integration can compromise the entire application surface, making security a first-class concern in API consumption.
To reduce risk, enforce strong authentication, encryption, input validation, and access control during integration. In addition, regular security audits and penetration testing help uncover and fix vulnerabilities before attackers do.
Implement strong authentication and authorization
Authentication confirms identity, while authorization defines what that identity can access. Together, they form the backbone of API security. Without strong controls, unauthorized access can lead to data breaches, privilege escalation, or abuse of backend services.
Choose the right token format. JSON Web Tokens (JWTs) are ideal for stateless applications since they directly carry authentication context and claims. However, validate tokens properly, avoid storing sensitive data in them, and securely manage expiration and revocation.
Use OAuth 2.0 with scoped tokens for third-party or delegated access. It issues access tokens with limited scopes and expiration, minimizing the potential impact of a compromised token. Implement refresh tokens to avoid repeatedly prompting users while still maintaining short-lived access tokens.
Enforce role-based access control (RBAC). Define roles and permissions explicitly within your system. Scope each API token or key based on what the client needs. For example, a read-only analytics client shouldn't be granted write access to user data.
Protect sensitive credentials. Never hardcode API keys or credentials in source code. Use environment variables, secret managers (like AWS Secrets Manager or HashiCorp Vault), or encrypted configuration files depending on your environment.
Encrypt API requests and responses
When transmitted over public networks without encryption, sensitive data such as credentials, personal information, financial records, etc., becomes vulnerable to interception and tampering. Encrypt API requests and responses to protect the confidentiality and integrity of communications and shield them from man-in-the-middle (MITM) or impersonation attacks.
Ensure all API endpoints use HTTPS backed by TLS version 1.2 or higher. Reject plain HTTP requests and redirect them securely. Disable outdated protocols like TLS 1.0 and 1.1, which are known to have security flaws.
Select well-supported cipher suites that offer forward secrecy. Avoid using deprecated algorithms like RC4, DES, or 3DES. Regularly review your encryption configuration to keep up with evolving best practices.
Use HTTP Strict Transport Security (HSTS) to prevent downgrade attacks that try to strip away encryption. It instructs browsers and clients to always connect over HTTPS, even if a user manually enters an HTTP address.
Apply application-level encryption on top of TLS for sensitive information such as health or payment data. This ensures the data remains protected even across intermediaries or service boundaries.
Validate incoming requests to prevent attacks
Every incoming API request is a potential entry point for malicious input. Attackers target APIs with injection attacks, forged requests, or unauthorized cross-origin access. Validating and sanitizing inputs is the first line of defense against these threats. It ensures that only well-formed, authorized, and expected data reaches the API backend.
Start by validating all incoming data, such as query parameters, headers, request bodies, and even file uploads. Enforce strict data types and use whitelists wherever possible. For example, if a parameter only contains an email address, apply a proper format check and reject anything that doesn’t match.
To protect against SQL injection, avoid building queries by concatenating strings. Instead, use parameterized or prepared statements in your database layer. This ensures that input is treated as data, not executable code.
Apply a strict CORS (Cross-Origin Resource Sharing) policy for cross-origin requests. Only allow trusted origins to interact with your API. Avoid setting Access-Control-Allow-Origin: * unless your API is genuinely public and unauthenticated.
Cross-Site Request Forgery (CSRF) is another common vector, particularly for browser-based clients. For state-changing operations, implement anti-CSRF tokens that verify the legitimacy of the request. These tokens should be unique per session and verified on the server side before processing any action.
Full-stack session recording
Learn more





When done right, input validation and security controls drastically reduce your attack surface. They also add predictability and stability to the API integrations, preventing unexpected behavior triggered by malformed or hostile input.
Conduct regular security audits and penetration testing
Even well-secured APIs can develop vulnerabilities over time. New features, shifting dependencies, and infrastructure changes can quietly introduce risk. Perform regular audits and testing to identify these issues early and keep integrations secure.
Schedule regular audits. Review access controls, authentication flows, and API activity logs. Look for unused credentials, overly broad roles, or any signs of privilege escalation.
Use automated vulnerability scanners. These tools help detect common issues such as weak encryption settings, token mismanagement, or input validation gaps. They're ideal for covering large surface areas quickly.
Run manual penetration tests. Automated tools can't catch everything. Pen testers can simulate complex attack paths by chaining smaller issues together. This is especially important for critical or exposed APIs.
Rotate API keys and credentials frequently. Replace API keys, tokens, and secrets on a set schedule. Use a secrets manager to store them securely, and immediately revoke any credentials that may have been exposed in logs, repositories, or CI/CD pipelines.
Organizations can avoid potential threats and ensure API communications remain secure by maintaining a proactive security posture.
Implement API versioning and compatibility strategies
Ensuring a secure and performant API is only one aspect of an effective strategy. As APIs evolve, new features are introduced, and breaking changes are made, producers must ensure they remain usable.
Versioning is the practice of managing and communicating these changes by maintaining multiple API versions simultaneously. It allows producers to introduce improvements and updates without disrupting existing consumers, giving developers time to adapt their integrations at their own pace. Proper versioning helps prevent compatibility issues, reduces integration errors, and provides a clear path for deprecation and migration. Let’s explore some techniques that can help with this.
Employ semantic versioning
Adopting a semantic versioning (SemVer) model allows API consumers to distinguish between minor updates and significant breaking changes. SemVer uses the scheme MAJOR.MINOR.PATCH. For example:
- A patch update (1.4.3) fixes bugs without changing the API contract (e.g., correcting a typo in a response message or fixing an internal calculation error).
- A minor update (1.5.0) adds backward-compatible features, like a new optional field in the JSON response or a new query parameter that doesn’t break existing clients.
- A major update (2.0.0) introduces breaking changes, such as renaming or removing API endpoints, changing request or response formats, or modifying authentication methods in a way that will prevent older clients from working without updates.
Maintain multiple versions in parallel
Supporting at least two API versions concurrently gives clients time to migrate without disruption. APIs can expose versions through URL pathing, headers, or query parameters.
For example, the code below utilizes FastAPI to fetch user data from two different API path versions that return data in different formats:
from fastapi import FastAPI
from typing import List
from models import UserV1, UserV2
from services import fetch_users
app = FastAPI()
@app.get("/v1/users", response_model=List[UserV1])
async def get_users_v1():
users = await fetch_users()
return [UserV1(id=u["id"], username=u["username"]) for u in users]
@app.get("/v2/users", response_model=List[UserV2])
async def get_users_v2():
users = await fetch_users()
return [UserV2(**u) for u in users]While path versioning (https://api.example.com/v1/resource) is the most common approach, some APIs prefer header-based versioning for cleaner URLs. For example:
GET https://api.example.com/users
Accept: application/vnd.example.v2+jsonInteract with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Sunset outdated API versions
While maintaining multiple API versions in parallel gives consumers time to transition, producers must eventually deprecate and retire older versions to reduce maintenance overhead and encourage the adoption of improved versions.
Be sure to deprecate legacy APIs gradually to avoid disruption. Start by monitoring usage to identify clients still relying on outdated versions. When planning a future deprecation, document it clearly and broadcast it in various ways, including in the official API documentation and change logs, via email/dashboard notifications, and via deprecation headers to inform clients programmatically.
HTTP/1.1 200 OK
Deprecation: true
Sunset: Thu, 31 Dec 2025 23:59:59 GMT
Warning: 299 - This API version will be deprecated in six months. Be sure that all announcements provide clear timelines and specify exact dates for key milestones, including when the deprecated version stops receiving updates, when support ends, and the final retirement date.
Provide integration guides for developers
The easier it is for developers to integrate with and start using your API, the more likely it is to be widely adopted. Many API producers invest significant time and effort in creating documentation that is clear, practical, and effective. However, traditional static docs often fall short in conveying the dynamic nature of APIs or demonstrating real-world usage.
To bridge this gap, tools like Multiplayer notebooks enable you to create rich, interactive integration guides combining API calls, code snippets, and step-by-step instructions. Developers can:
- Create text blocks to document step-by-step instructions, system requirements, design decisions, Architectural Decision Records (ADRs), technical debt, and more.
- Build executable blocks to design, document, and sequence API calls alongside runnable code snippets.
- Run these executable blocks to test APIs and code in real-time within the guide.
Notebooks can be authored manually, generated from natural language using AI, or created automatically from a Multiplayer full stack session recording with runnable test scripts.


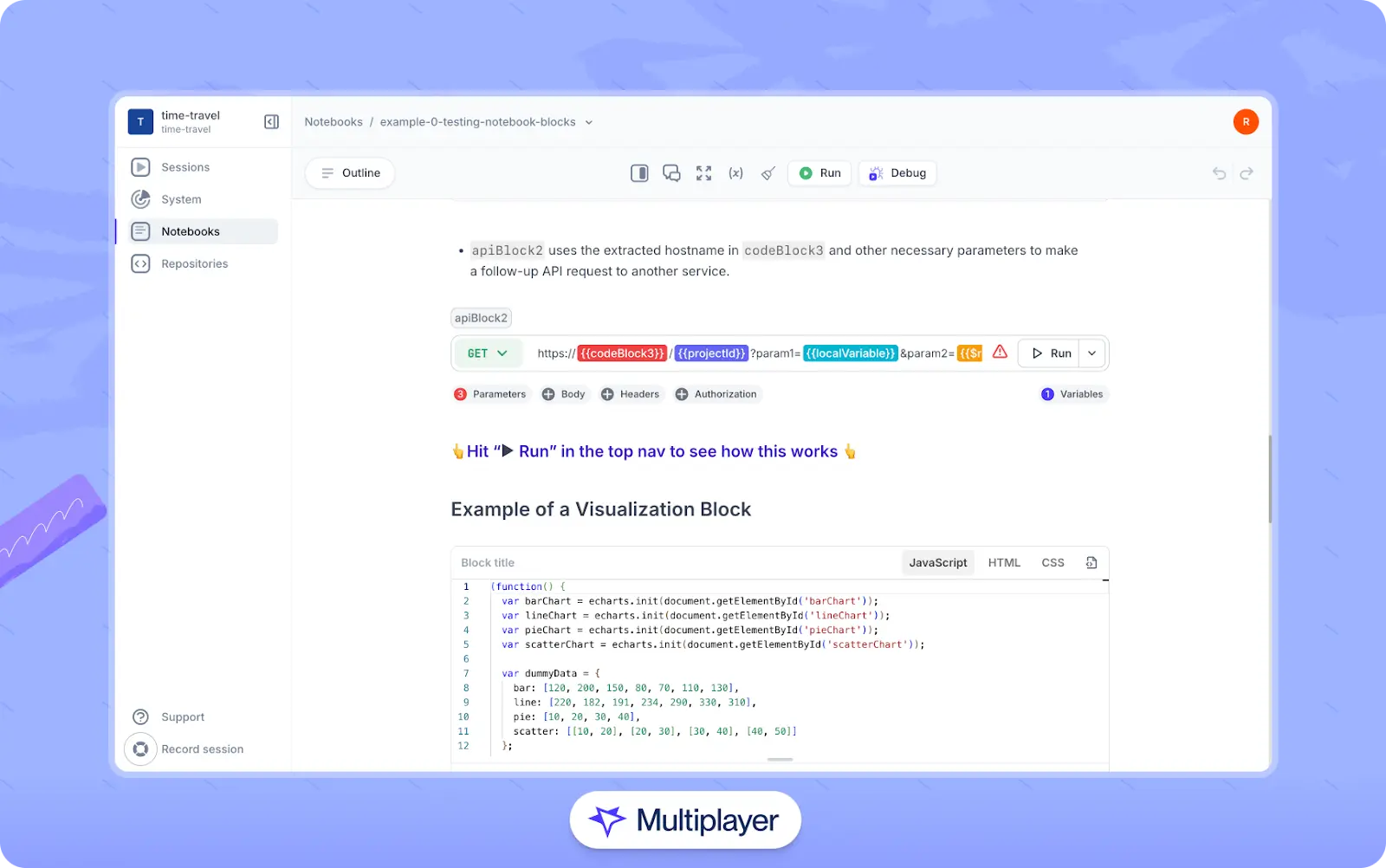
Multiplayer notebooks
API integration best practices for API consumers
Now that we have explored best practices from the perspective of API producers, let’s turn to API consumption: The process by which a client application integrates with and uses internal and external APIs. Effective consumption requires attention to many factors, including:
- Understanding authentication and authorization mechanisms
- Respecting rate limits and quotas to avoid throttling or service denial
- Parsing and constructing data in the correct formats
- Minimizing the number of API calls to control costs and improve performance
- Monitoring API usage, response times, and error trends over time
Some of the biggest challenges in consuming APIs stem from two fundamental realities:
- Consumers have little or no control over the performance, reliability, or internal implementation of the APIs they consume.
- Effective consumption requires a deep understanding of the consuming system’s architecture and data flow.
While these may seem like simple considerations, they have far-reaching implications. The inevitable disruptions and failures of the APIs you depend on influence how you design systems for resilience and fault tolerance. Meanwhile, a lack of system understanding can result in:
- Incorrect API interfaces or mismatched expectations
- Redundant or unnecessary components
- Duplicated effort across teams
- Painfully inefficient debugging and troubleshooting
In this section, we explore best practices that address these issues.
Design resilient and fault-tolerant API calls
As stated above, a well-designed API integration anticipates failures and implements strategies to recover gracefully. Without fault tolerance, even transient errors (like timeouts or network hiccups) can escalate into system-wide issues, degrading user experience and causing avoidable downtime. To prevent this, implement fallback mechanisms that make your API consumption resilient and self-recovering.
Retry mechanisms with exponential backoff
Exponential backoff is a strategy where the delay between retries increases exponentially after each failure. This approach prevents overwhelming the target API with rapid retries, gives external services time to recover, and improves the chances of success in unstable conditions.
For example, in Python, an exponential backoff retry mechanism using asyncio and aiohttp looks like this.
import aiohttp
import asyncio
async def make_request_with_backoff(url, max_retries=5):
retries = 0
backoff_factor = 2
async with aiohttp.ClientSession() as session:
while retries < max_retries:
try:
async with session.get(url, timeout=aiohttp.ClientTimeout(total=5)) as response:
response.raise_for_status()
return await response.json()
except Exception as e:
wait_time = backoff_factor ** retries
print(f"Retry {retries + 1}: Waiting {wait_time} seconds due to {e}")
await asyncio.sleep(wait_time)
retries += 1
raise Exception("Max retries reached. Request failed.")It ensures that temporary failures do not result in unnecessary system failures while preventing aggressive retry loops that could overload the API.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREECircuit breakers
The circuit breaker system design pattern prevents cascading failures that could impact overall system stability. It protects the system by detecting repeated failures and temporarily blocking requests for a failing integration.


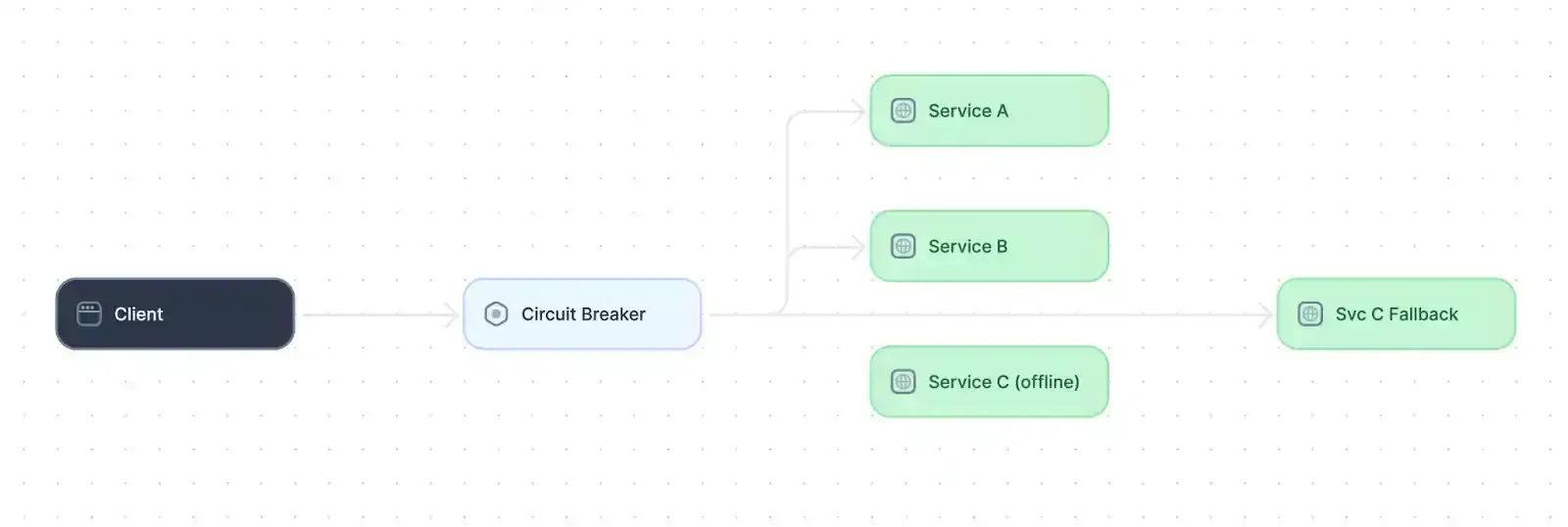
Example of a circuit breaker design pattern (source)
A circuit breaker generally has three states:
- Closed: Requests are allowed as long as they succeed.
- Open: After multiple failures, requests are temporarily blocked to allow recovery.
- Half-open: The system tests if the service has recovered before resuming normal operations.
In the half-open state, the circuit breaker allows a limited number of requests to flow through the system. If they succeed, the circuit breaker moves back into the closed state. If they continue to fail, it moves back to the open state to avoid timeouts, give the failing service time to recover, and prevent failures from cascading through the system.
Let’s take a look at how this looks using the opossum library in Node.js:
const CircuitBreaker = require('opossum');
function asyncFunctionThatCouldFail(x, y) {
return new Promise((resolve, reject) => {
// Simulated operation that fails 70% of the time
if (Math.random() < 0.7) {
reject(new Error("Simulated failure"));
} else {
resolve(`Success with x=${x}, y=${y}`);
}
});
}
const options = {
timeout: 3000, // Trigger a failure if it takes longer than 3 seconds
errorThresholdPercentage: 50, // Trip the circuit if 50% of requests fail
resetTimeout: 10000 // After 10 seconds, try again
};
const breaker = new CircuitBreaker(asyncFunctionThatCouldFail, options);
// Exponential backoff retry wrapper
async function callWithExponentialBackoff(x, y, retries = 5, baseDelay = 500) {
for (let i = 0; i < retries; i++) {
try {
const result = await breaker.fire(x, y);
console.log(`Attempt ${i + 1}: Success`);
return result;
} catch (err) {
console.error(`Attempt ${i + 1} failed:`, err.message);
if (i < retries - 1) {
const delay = baseDelay * 2 ** i + Math.random() * 100; // jitter
console.log(`Waiting ${Math.round(delay)}ms before retrying...`);
await new Promise(resolve => setTimeout(resolve, delay));
} else {
console.log(`All ${retries} attempts failed.`);
throw err;
}
}
}
}This code wraps a function with an opposum circuit breaker and adds exponential backoff retry logic to handle transient failures. If a call fails, it retries up to 5 times with exponentially increasing delays before giving up and throwing the final error.
Graceful degradation strategies
Graceful degradation is reducing system functionality in a controlled and user-friendly way when an API becomes unavailable. Rather than allowing the entire system to fail, it continues operating with limited or approximate features. Development teams can implement fallback strategies that maintain a usable experience. For example,
Serve cached data. When live data from an integrated service is unavailable, fall back to previously cached responses. Even if slightly outdated, this can be sufficient for many user-facing features, such as follower counts or content previews.
Use fallback mechanisms. Route traffic to backup APIs or approximate the result. For example, if a weather API fails, your app might use a secondary provider or show a daily average based on recent historical data.
Handle timeouts. Instead of letting a request to a slow or failing service hang indefinitely, implement timeouts and handle failures gracefully by falling back or providing default responses.
Regardless of which strategies are implemented, it is essential to handle errors in a user-friendly way. Display clear, actionable messages and avoid dead-end failure states, such as showing “500 Internal Server Error.” Provide meaningful error messages and ensure the UI remains responsive in the face of service interruptions.
Understand your integration environment
API integrations added to poorly understood systems can introduce data inconsistencies, unexpected failures, and unnecessary complexity. Before integrating, identify the current system state and how data moves between different internal and external services. Achieving this requires a combination of service mapping, observability, and clear, up-to-date documentation. Let’s explore what that looks like in practice.
Service mapping
Service mapping identifies and documents the relationships and dependencies between services and the underlying infrastructure that supports them. This can be done manually or using automated tooling.
Manual service mapping, especially in large-scale systems, is tedious and error-prone. It often depends on outdated documentation, tribal knowledge, and hand-drawn diagrams of components and their dependencies. Maintaining accuracy typically requires regular meetings and frequent updates, which can be time-consuming and challenging to scale.
Because of these issues, automated discovery tools have emerged to ease this process. For example, Multiplayer’s system dashboard automatically detects components, APIs, and dependencies; summarizes information across them, and generates architecture diagrams to provide developers with a high-level overview of their systems.


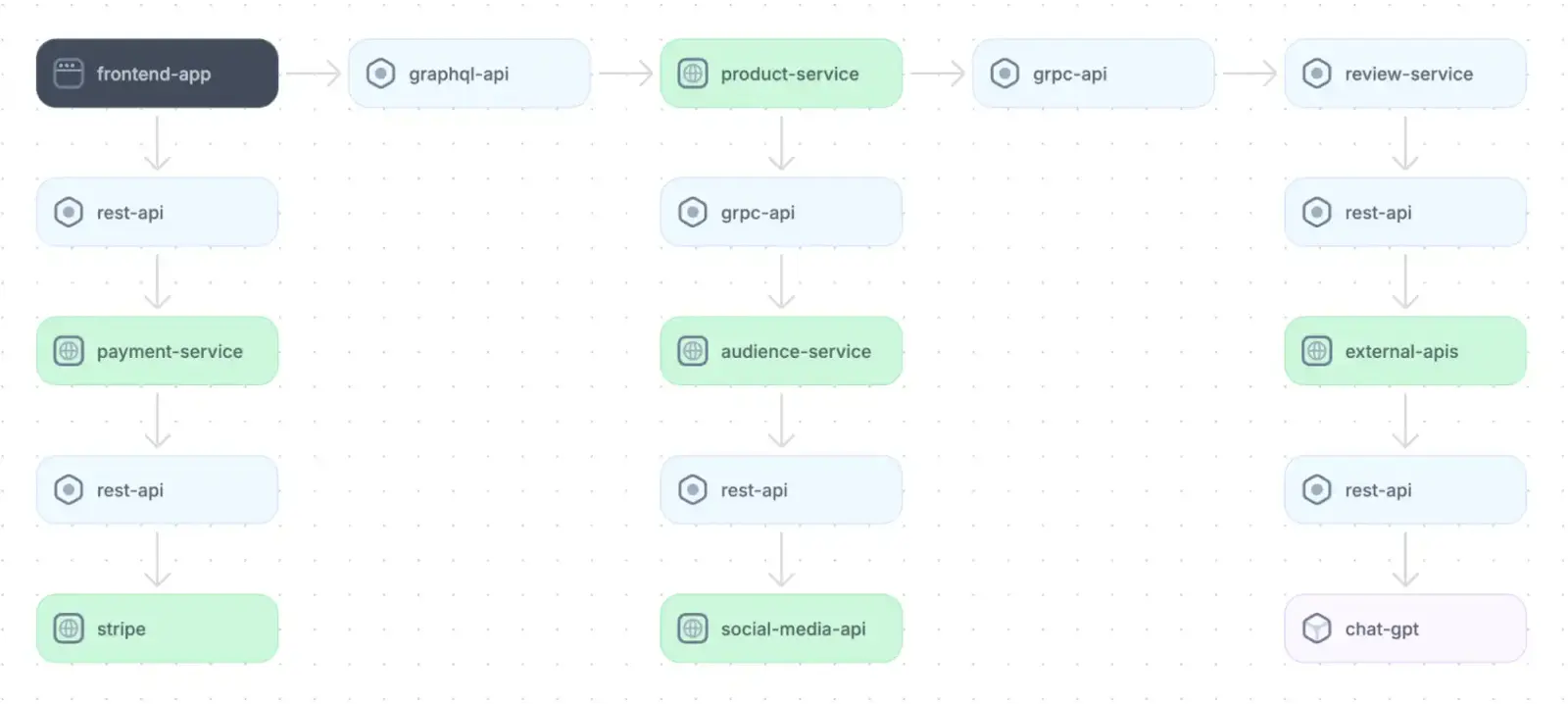
Application architecture diagram for an e-commerce platform
Such a map provides an important foundation and helps teams to identify how and where to integrate new APIs safely.
Analyzing API dependencies and third-party service limitations
Any application dependency–whether internal or third-party–has the potential to fail or experience performance degradation. Understanding these risks allows your team to plan alternative workflows to mitigate the impacts of dependency issues. To do so, employ the following strategies:
- Monitor external API health and plan for alternative workflows to reduce risks associated with dependency failures.
- Health-check endpoints and continuously track response times, error rates, and availability using observability tools.
- Implement automated monitoring to periodically analyze the API dependencies and third-party services for timely detection and handling of failures.
Tracking requests and identifying failure points in the data pipeline
When production issues hit, developers need clarity fast. However, tracing a failed API call through the frontend, backend, and infrastructure is often slow and fragmented.
Start with the essentials: log failed requests, response times, and recurring errors. Correlate client-side issues with backend behavior to isolate the source. To scale it further, use comprehensive monitoring strategies such as P99s, P95s, etc. This helps uncover unreliable endpoints, performance bottlenecks, or breaking changes.
In addition, consider integrating Multiplayer’s full stack session recordings into your team’s workflow. Recordings enhance debugging by automatically capturing the entire request lifecycle, from frontend screens to backend traces, logs, and response details. Developers can also annotate recordings to turn them into development plans and use Multiplayer’s MCP server to feed recording data, screenshots, and annotations to AI coding tools to generate more accurate fixes, tests, and features.

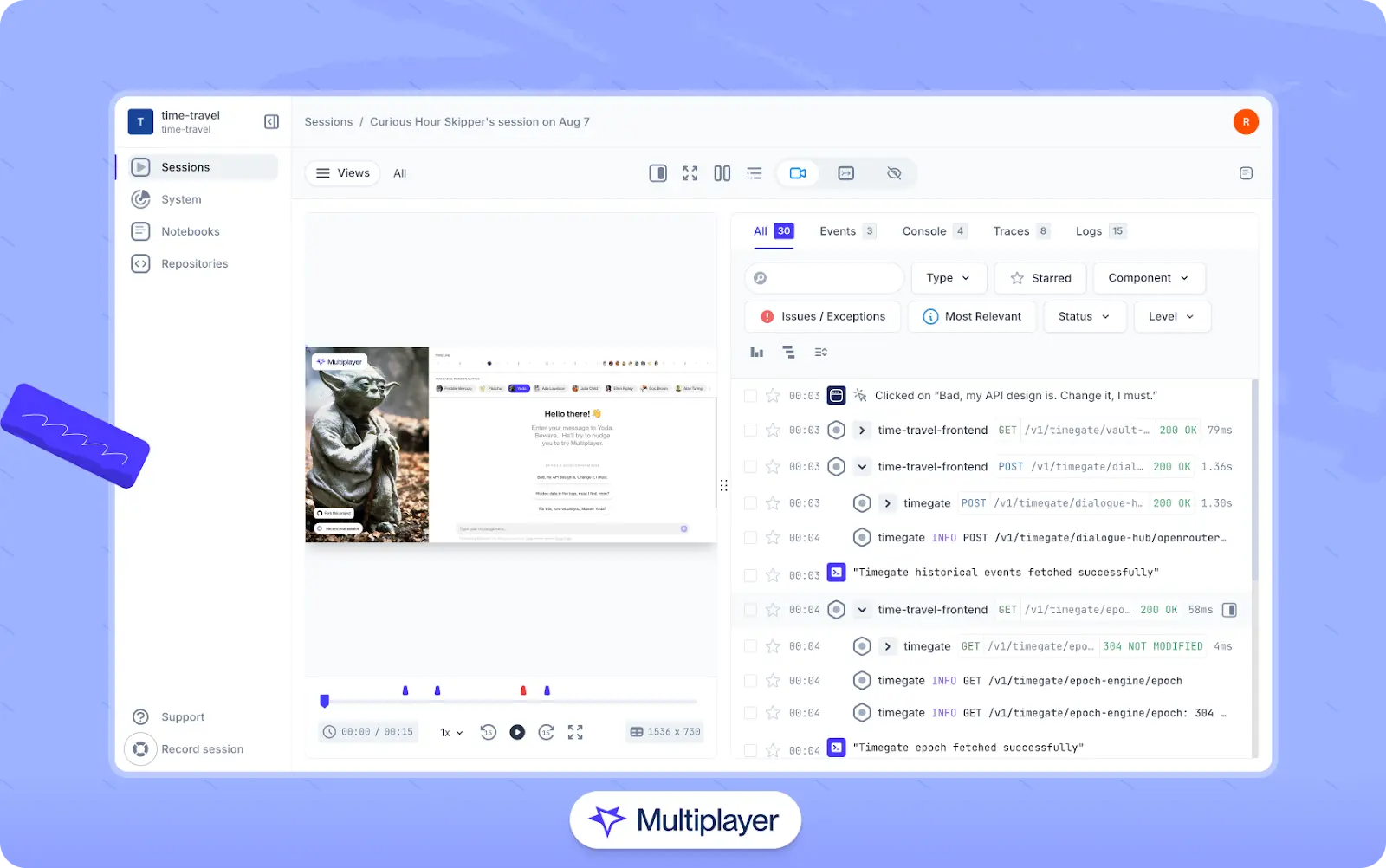
Multiplayer full stack session recordings
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREELast thoughts
Building robust API integrations requires a strategic approach that balances reliability, security, and performance. Developers can ensure seamless and scalable interactions between services by understanding the integration environment, designing fault-tolerant API calls, securing communication channels, and optimizing request handling. Effective versioning and migration strategies prevent disruptions, while proactive monitoring and debugging streamline issue resolution.
Leveraging tools like Platform Notebooks for migration guidance and Platform Debugger for real-time diagnostics enhances integration quality and maintainability. A well-integrated API ecosystem accelerates development, ensuring long-term adaptability in an evolving software landscape.